# Архитектура компьютера ## Лекция 7-8-9 ## Универсальный процессор. <br/> Машина фон Неймана. Память. Принципы DataPath. <br/> CISC. RISC. Stack Пенской А.В., 2025 --- ## Информационный процессор <div class="row"><div class="col"> <dl> <dt> Информационный процессор </dt> <dd> система (электрическая, механическая или биологическая), которая принимает информацию (последовательность символов или состояний) в одной форме и обрабатывает (преобразует) ее в другую форму. </dd> </dl> Например: исходный сигнал в статистику, посредством алгоритмического процесса. </div><div class="col"> 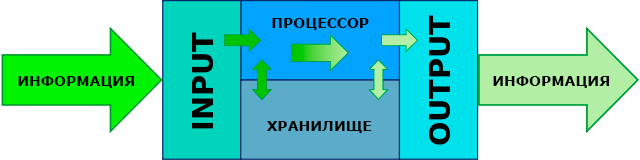 Информационный процессор включает: 1. ввод 1. процессор 1. хранилище 1. вывод </div></div> ---- ### Универсальный процессор Позволяет решать широкий круг задач, настройка которых производится после производства "по месту" или в run-time. Примечания: 1. Универсальность $\neq$ полнота по Тьюрингу. 1. Теоретическая универсальность $\neq$ практическая универсальность. 1. Универсальность противоречит эффективности. 1. Современный процессор — совокупность программного и аппаратного обеспечения. <!-- ### Свойства универсального (программируемого) процессора --> Свойства: 1. 2-этапное производство (Hardware и Software) 1. Полнота по Тьюрингу 1. Отсутствие "серьезных" ограничений на "объём" программы 1. Изменяемость ПО --- ## Виды процессоров Гибкость и эффективности  <!-- .element: height="300px" --> <div class="row"><div class="col"> (1) Application-Specific Integrated Circuit (2) Coarse-Grained Reconfigurable Arrays <br/> (3) Field-Programmable Gate Array </div><div class="col"> (4) Digital Signal Processor <br/> (5) Graphics Processing Unit <br/> (6) **Central Processing Unit** <br/> </div></div> ---- ### Платформа и язык программирования  <!-- .element: height="550px" --> --- ### Архитектура процессора <dl> <dt> Архитектура процессора (architecture) </dt> <dd> то, как видит компьютер программист. Определена набором команд (язык), местом нахождения операндов (регистры и память) и вычислительными механизмами (кеш, прерывания...). </dd> </dl> -------------------- 1. Множество разных архитектур: - x86, MIPS, SPARC, ARM. - acc, cisc, risc, stack (элемент варианта лаб. 4) 1. Чтобы понять архитектуру, нужно знать её язык. 1. Слова в языке компьютера — "инструкции" или "команды". 1. Словарный запас — "система команд". ---- ### Микроархитектура процессора <dl> <dt> Микроархитектура процессора (microarchitecture) </dt> <dd> соединение простейших цифровых элементов в логические блоки, предназначенные для выполнения команд определенной архитектуры. </dd> </dl> -------------------- Примечания: 1. Описывает, как в процессоре расположены и соединены друг с другом регистры, АЛУ, конечные автоматы, блоки памяти, интерфейсы ввода-вывода и т.п. 1. У каждой архитектуры может быть много микроархитектур, обеспечивающих разное соотношение производительности, цены, сложности, технической эстетики. Они смогут выполнять одни и те же программы. 1. Если ISA и микроархитектура отличаются на уровне MoC — обычно требуется уровень виртуализации (ПО, аппаратура. транслятор...). ---- #### Система команд (ISA) <div class="row"><div class="col"> <dl> <dt> Система команд процессора </dt> <dd> (Instruction Set Architecture — ISA) абстрактная модель процессора, формирующая интерфейс взаимодействия между программным обеспечением и процессором. </dd> </dl> Производительность, энергопотребление и задержки часто не рассматриваются. <dl> <dt> Машинное слово </dt> <dd> фрагмент данных фиксированного размера, обрабатываемый как единое целое процессором. </dd> </dl> </div><div class="col"> 1. типы данных, 1. модель памяти, система и методы адресации, 1. набор инструкций, 1. механизмы обработки прерываний и исключений, 1. методы ввода и вывода.  <!-- .element: height="300px" --> </div></div> Notes: ECE C61 Computer Architecture Lecture 3 – Instruction Set - [Meltdown and Spectre](https://meltdownattack.com) - [Edward A. Lee Modeling in Engineering and Science](https://cacm.acm.org/magazines/2019/1/233519-modeling-in-engineering-and-science/fulltext) ---- #### Разнообразие систем команд Примеры разных команд (утрировано): 1. Действие над памятью/регистрами (фон Нейман): $\longrightarrow$ - произвольной сложности и длины (CISC), - фиксированного формата (RISC). 1. Действие без указания обрабатываемых данных (стековый). 1. Управляющие сигналы процессора под видом команды (NISC). 1. Группа команд под видом одной команды (VLIW). 1. Действие над шиной данных (TTA). 1. Команды без последовательного исполнения (редукционные). 1. Система команд из одной команды (URISC). 1. Управляющие сигналы процессоров под видом команды (NITTA). Notes: слишком много ссылок в будущее, надо как-то упростить. --- ## Машина фон Неймана <div class="row"><div class="col"> 1. Развитие машины Тьюринга. Ключевые отличия: - лента заменена на Random-Access Memory (RAM); - инструкции и данные объединены. 1. Призвана быть максимально простой в реализации и производстве. 1. Процедурное программирование и ООП — тот же принцип. </div><div class="col">  </div></div> ---- ### Машина фон Неймана. Особенности 1. Использование двоичного кодирования. - Встречается троичное и двоично-десятичное кодирование. 1. Программное управление. Команды выполняются последовательно. - Последовательность и порядок сегодня условны. 1. Память компьютера однородно хранит данные и программы. - Однородность спорна. 1. Ячейки памяти компьютера имеют адреса. Random-Access Memory. - Адрес не сводится к целому числу сегодня. - Память не является пассивным элементом компьютера. 1. Возможность условного перехода. - И перехода по иным причинам. ---- <div class="row"><div class="col"> #### Машина фон Неймана. Окружение <dl> <dt> [Микро]процессор </dt> <dd> цифровая схема, которая выполняет операции с внешним источником данных (обычно памятью или потоком данных). </dd> </dl> <dl> <dt> [Микро]контроллер </dt> <dd> микросхема, предназначенная для управления электронными устройствами. </dd> <dd> Типичный микроконтроллер сочетает функции процессора и периферийных устройств, содержит ОЗУ и (или) ПЗУ. </dd> </dl> </div><div class="col">  <dl> <dt> Оперативная память (память) </dt> <dd> обычно часть компьютерной памяти, в которой хранится выполняемый машинный код, а также входные, выходные и промежуточные данные. </dd> </dl> </div></div> ---- #### Машина фон Неймана. Control Unit и DataPath <div class="row"><div class="col"> <dl> <dt> Control Unit </dt> <dd> is a component of a computer's central processing unit (CPU) that directs the operation of the processor. A CU typically uses a binary decoder to convert coded instructions into timing and control signals that direct the operation of the other units. </dd> </dl> <dl> <dt> Datapath </dt> <dd> is the ALU, the set of registers, and the CPU's internal bus(es) that allow data to flow between them. </dd> </dl> Компоненты модели лаб. 4 </div><div class="col">   </div></div> ---- #### Машина фон Неймана. Виды инструкций <div class="row"><div class="col"> 1. **Работа с памятью**: запись констант, копирование данных (память, регистры, порты I/O). 2. **Арифметические, логические и битовые** операции (int, float). 3. **Управляющие операции**: безусловный, условный и косвенный переходы, вызов и возврат из подпрограмм. 4. **Инструкции сопроцессоров**: - Загрузка и выгрузка данных. - Управление сопроцессором. </div><div class="col">  - `OP Code` — код операции. - `Addr 1/2` — номера регистров общего назначения. - `Immediate value` — непосредственное значение. - `$r1` `<- $r2 + 350` - При переполнении: - `$r1` — без изменений, - установить флаг overflow. </div></div> ---- #### Машина фон Неймана. Роль машинного слова Единица данных, которая выбрана естественной для данной архитектуры процессора. 1. Может быть адресована в памяти. 1. Передаётся по шине между памятью и процессором за один раз. 1. Является стандартной единицей обрабатываемой информацией. 1. Связанные вопросы: - формат инструкции; - форматы данных; - форматы адресов. --- ### Машина фон Неймана. Пример программы Программа — последовательность инструкций в памяти компьютера. - Последовательное исполнение инструкций с условными переходами. - Инструкции изменяют состояние процессора. - Последовательная модель вычислений. ```text | Address | Mnemonic | Comment | | ------- | -------------- | ----------------------------------------- | | 0400 | MOV CX, [0500] | CX <- [0500] | | 0404 | MOV AX, 0001 | AX <- 0001 | | 0407 | MOV DX, 0000 | DX <- 0000 | | 040A | MUL CX | DX:AX <- AX * CX | | 040C | LOOP 040A | Go To [040A] | | | | till CX->00 (CX <- CX - 1 on each step) | | 0410 | MOV [0600], AX | [0600]<-AX | | 0414 | MOV [0601], DX | [0601]<-DX | | 0418 | HLT | Stop Execution | ``` - Алгоритм расчёта факториала: - Входные данные по адресу `0500` равны 3. - Результат сохранить по адресам `[0600, 0601]`. ---- #### Машина фон Неймана. Пример трассы процесса Трасса процесса — очерёдность смены состояний процессора. ```text 1. {AX: x, CX: x, DX: x} Выполняется 0400 | MOV CX, [0500] 2. {AX: x, CX: 3, DX: x} Выполняется 0404 | MOV AX, 0001 3. {AX: 1, CX: 3, DX: x} Выполняется 0407 | MOV DX, 0000 3.1. {AX: 1, CX: 3, DX: 0} Выполняется 040A | MUL CX 3.2. {AX: 3, CX: 3, DX: 0} Выполняется 040C | LOOP 040A CX не равно 0, переходим 040A. 3.3. {AX: 3, CX: 2, DX: 0} Выполняется 040A | MUL CX 3.4. {AX: 6, CX: 2, DX: 0} Выполняется 040C | LOOP 040A, CX не равно 0, переходим 040A 3.5. {AX: 6, CX: 1, DX: 0} Выполняется 040A | MUL CX 3.6. {AX: 6, CX: 1, DX: 0} Выполняется 040C | LOOP 040A, после декремента CX равно 0, выполняем следующую инструкцию. 4. {AX: 6, CX: 0, DX: 0} Выполняется 0410 | MOV [0600], AX 5. {AX: 6, CX: 0, DX: 0} Выполняется 0414 | MOV [0601], DX 6. Выполняется 0418 | HTL, Остановить выполнение ``` Регистры `AX`, `DX`, `CX` — брошены в "случайном" состоянии. ---- ### Машина фон Неймана. Практика 1. В чистом виде практически не встречается. 1. Влияние на индустрию — трудно переоценить. 1. Элементы архитектуры присутствуют в подавляющем большинстве процессоров и средств разработки. 1. Структурное программирование, ООП — наследие фон Неймана. 1. Ловушка обратной совместимости. > Can Programming be Liberated from the von Neumann Style? — Backus, John. 1977 Turing Award Lecture <!-- Попытка сделать эскиз современного процессора:  --> --- ### Машина фон Неймана. Вариации 1. Память команд и данных: Принстонская и Гарвардская архитектуры - Типы данных, адресные пространства, машинные слова, теги 1. Принцип работы с данными в DataPath - Accumulator, Register-to-Register, Register-to-Memory, Memory-to-Memory, Stack Architectures 1. "Мощность" системы команд: CISC, RISC - Количество операндов (0, 1, 2...) - Кодирование инструкций - Принципы построения Control Unit 1. Адресация операндов: ```text - подразумеваемая (OpCode) - укороченная (часть адреса) - непосредственная (hardcode) - косвенная (адрес в ячейке) - прямая (числом) - адресация слов переменной длины - относительная (`addr + base`) - стековая - автоинкрементная и автодекрементная ``` Кроме того: ввод-вывод, параллелизм, иерархия памяти, и т.п. --- ### Память инструкций и данных. <br/> Принстонская и Гарвардская архитектуры <div class="row"><div class="col"> **Принстонская архитектура (фон Неймановская)**. Узкое место — совместная память: - доступ к инструкциям и данным - по очереди по одному каналу. </div><div class="col"> **Гарвардская архитектура**. Памяти разделены: - память инструкций и память данных — разные устройства, - каналы инструкций и данных физически разделены. </div></div>  ---- #### Гарвардская архитектура. Особенности ##### Достоинства 1. Два физических канала между процессором и памятью. 1. Одновременный доступ к памяти. 1. Разная ширина машинного слова и адреса для данных и программ. - Оптимизация под решаемую задачу. 1. Изоляция памяти инструкций. ##### Недостатки 1. Сложность и стоимость реализации. 1. Изоляция инструкций и данных: - Запуск результата компиляции. - Указатели на функции. *Вопрос*: От чего зависит размерность машинных слов <br/> и адресных пространств? ---- #### Вариации Гарвардской архитектуры <dl> <dt> Архитектура "Память инструкций как данные" <br/> (Instruction-memory-as-data) </dt> <dd> реализуется возможность читать и писать данные в память программ. Позволяет генерировать и запускать машинный код. </dd> </dl> -------------------- <dl> <dt> Архитектура "Память данных как инструкции" <br/> (Data-memory-as-instruction) </dt> <dd> реализует возможность запуска инструкций из памяти данных. Позволяет генерировать и запускать машинный код, но параллельный доступ ограничен. </dd> </dl> -------------------- <dl> <dt> Модифицированная Гарвардская архитектура (main stream) </dt> <dd> Доступ к памяти реализуется через независимые кеши для данных и программ, за счет чего, с точки зрения внутренней организации процессора, доступ реализован независимо, при этом канал между процессором и памятью один. </dd> </dl> --- ### Принцип работы с данными в DataPath 1. Accumulator Architectures 1. Register-to-Memory Architectures 1. Register-to-Register Architectures 1. Memory-to-Memory Architectures 1. Stack Architectures Источник: ECE C61 Computer Architecture Lecture 3 — Instruction Set ---- #### Accumulator Architectures  ---- #### Register-to-Memory Architectures  ---- #### Register-to-Register: Load-Store Architectures  ---- #### Memory-to-Memory Architectures  ---- #### Stack Architectures  --- ### Система команд и линейная функции <div class="row"><div class="col"> ```asm load ACC <- A ; acc mul ACC <-* B ; 1 operands add ACC <-+ C store Y <- ACC ; (1) ``` ```asm load R1 <- A ; reg-to-mem mul R1 <- R1 * B ; 1 operands add R1 <- R1 + C store Y <- R1 ; (2) ``` ```asm load R1 <- A ; reg-to-reg load R2 <- X ; 2 operands load R3 <- B mul R4 <- R1 * R2 add R5 <- R4 + R3 store Y <- R5 ; (3) ``` ```asm load R1 <- A ; reg-to-reg load R2 <- X ; 3 operands load R3 <- B lnf R4 <- R1 * R2 + R3 store Y <- R4 ; (4) ``` </div><div class="col"> $Y = A * X + B$ ```asm mul R1 <- A * B ; reg-to-mem add Y <- R1 + C ; 2 operands (5) ``` ```asm lfn Y <- A * B + C ; mem-to-mem ; 3 operands (6) ``` ```forth A @ B @ * \ stack, 0 operands (7) C @ + Y ! \ @ - read, ! - write ``` Что лучше? - (1) — начало - CISC (2, 4, 5, 6) - RISC (3) - Stack (7) </div></div> Notes: зависит от алгоритма, неплохо бы оптимизировать под задачу. --- ## Машина фон Неймана. Пример <br/> Accumulator Architectures  ---- <div class="row"><div class="col"> ### Характеристики  - Регистры и флаги: - `PC` — счетчик команд - `IR` — регистр инструкций - `AR` — регистр адреса операнда - `C` — флаг переноса/займа - `Z` — флаг нуля </div><div class="col"> - Разрядность процессора: 8 бит. - Организация памяти: Гарвардская. - Внешние устройства отображаются в адресное пространство данных. Работа по опросу. - Команды выполняются за 2 или 3 такта: - Выборка команды. - Выборка операндов. - Выполнение команды. - Прерывания и команды вызова подпрограмм отсутствуют. [Пример модели процессора на Haskell](http://amazing-new-gate.blogspot.com/2010/07/haskell.html) </div></div> ---- ### Пример исполнения инструкции <div class="row"><div class="col">  ```asm add #01 <- 34 + #03 ; [ <opcode>, 34, 03, 01 ] 5t acc <- 34 ; [ <opcode>, 34 ] 2t acc <-+ #03 ; [ <opcode>, 03 ] 3t #01 <- Acc ; [ <opcode>, 01 ] 3t ``` 1. Реальное устройство DataPath может не соответствовать ISA. 1. Сложные инстр. эффективнее. </div><div class="col"> ```asm ;--------- 1. Чтение инструкции IR <- PMem[PC] PC <- PC+1 ;--------- 2. Инициализация акк. 34 { Acc, Z, C } <- ALU(...) <- MUX2(...) <- PMem[PC] PC <- PC+1 ;--------- 3. Выгрузка адреса 03 AR <- PMem[PC] PC <- PC+1 ;--------- 4. Выгрузка адреса 01 ;--------- Выгрузка #03 и сложение AR <- PMem[PC] { Acc, Z, C } <- ALU(...) <- MUX2(...) <- DMem[AR].DOUT PC <- PC+1 ;--------- 5. Сохранение результата DMem[AR].DIN <- Acc ``` </div></div> --- ## Complex Instruction Set Computer <dl> <dt> CISC </dt> <dd> is a computer architecture in which single instructions can execute several low-level operations (a load from memory, an arithmetic operation, and a memory store) or are capable of multi-step operations or addressing modes within single instructions. </dd> </dl> <div class="row"><div class="col"> Причины появления: - Низкоуровневые языки. - Разнообразие архитектур. - Неразвитость компиляторов. - Удобство программирования. - Высокая производительность. - Минимизация объёма программ. - Минимизация накладных расходов. </div><div class="col"> Проблемы: - Сложная система команд (использование, анализ). - Сложное устройство процессора и Control Unit. - Сложно генерировать эффективный машинный код. </div></div> ---- ### Подходы к реализации Control Unit <div class="row"><div class="col"> <dl> <dt> Hardwired </dt> <dd> при помощи аппаратных комбинационных схем, декодирующих инструкции в последовательности сигналов. </dd> </dl> <dl> <dt> Microcoded </dt> <dd> при помощи исполнения микропрограммы, реализующей необходимые функции. </dd> </dl> <dl> <dt> Микропрограмма (микрокод) </dt> <dd> программа, реализующая набор инструкций процессора. </dd> </dl> </div><div class="col">   </div></div> ---- <div class="row"><div class="col"> #### Микропрограммное управление. Пример /1 1. Выделяем сигналы управления: - защёлкивание регистров; - чтение/запись в память; - селекторы мультиплексоров. 2. Создаём память микрокоманд. Ширина слова соответствует количеству сигналов. 3. Определяем микрокоманды для поиска начала инструкций (`00-01`). 4. Реализуем механизм поиска `n1`. 5. Пишем микрокод для инструкций (`n1-n4`), завершаем их `mjmp 00`. </div><div class="col"> ```text 00 01 ... n1 n2 n3 n4 latch_PC 1 0 ... 1 1 1 0 mux_PC +1 0 ... +1 +1 +1 0 latch_IR 1 0 ... 0 0 0 0 latch_AR 0 0 ... 0 1 1 0 MUX2 0 0 ... PM 0 DM 0 ALU 0 0 ... +0 0 +A 0 OE 0 0 ... 0 0 1 0 WR 0 0 ... 0 0 0 1 latch_mPC 1 1 ... 1 1 1 1 mux_mPC +1 DC ... +1 +1 +1 =0 | +-- mpc <- decoder(IR) ```  </div></div> ---- <div class="row"><div class="col"> #### Микропрограммное управление. Пример /2 ```asm add #01 <- 34 + #03 ;--------- 1. Чтение инструкции IR <- PMem[PC] PC <- PC+1 ;--------- 2. Инициализация акк. 34 { Acc, Z, C } <- ALU(...) <- MUX2(...) <- PMem[PC] PC <- PC+1 ;--------- 3. Выгрузка адреса 03 AR <- PMem[PC] PC <- PC+1 ;--------- 4. Выгрузка адреса 01 ;--------- Выгрузка #03 и сложение AR <- PMem[PC] { Acc, Z, C } <- ALU(...) <- MUX2(...) <- DMem[AR].DOUT PC <- PC+1 ;--------- 5. Сохранение результата DMem[AR].DIN <- Acc ``` </div><div class="col"> ```text 00 01 ... n1 n2 n3 n4 latch_PC 1 0 ... 1 1 1 0 mux_PC +1 0 ... +1 +1 +1 0 latch_IR 1 0 ... 0 0 0 0 latch_AR 0 0 ... 0 1 1 0 MUX2 0 0 ... PM 0 DM 0 ALU 0 0 ... +0 0 +A 0 OE 0 0 ... 0 0 1 0 WR 0 0 ... 0 0 0 1 latch_mPC 1 1 ... 1 1 1 1 mux_mPC +1 DC ... +1 +1 +1 =0 | +-- mPC <- decoder(IR) ```  </div></div> ---- #### Поиск адреса микрокода для инструкции 1. **Алгоритмически**: сопоставление инструкции с условием + условный переход в рамках микропрограммы. 2. **Отображение кода операции на адрес микроинструкции** - **Прямое отображение** — opcode выступает в роли адресса. К примеру: opcode `0101` — `0x05` адрес микроинструкций. - **Непрямое отображение** — требует использования look-up-table для поиска нужного адреса (см. пример лаб. 4). ---- #### Микропрограммное управление <div class="row"><div class="col"> Достоинства: 1. Простота реализации сложных ISA (CISC). 2. "Программирование" системы команд. 3. Доступ к микрокоду для программиста. 4. Генерация ISA под задачу (сократить объём, повысить эффективность), см. [«Самсон»](https://www.computer-museum.ru/articles/sistemi_kompleksi/90/). </div><div class="col"> Недостатки: 1. Хранение микрокода в процессоре. 2. CISC долго учить. 3. Разнообразие архитектур $\rightarrow$ проблемы инструментария. 4. Разнообразие команд (форматы, размеры, длительности, доступ). Усложняет: - оптимизацию процессора; - инструментарий. 5. Микрокод привносит все проблемы программирования (сложность, отладка, методы). </div></div> --- #### No Instruction Set Computing (NISC) <div class="row"><div class="col"> 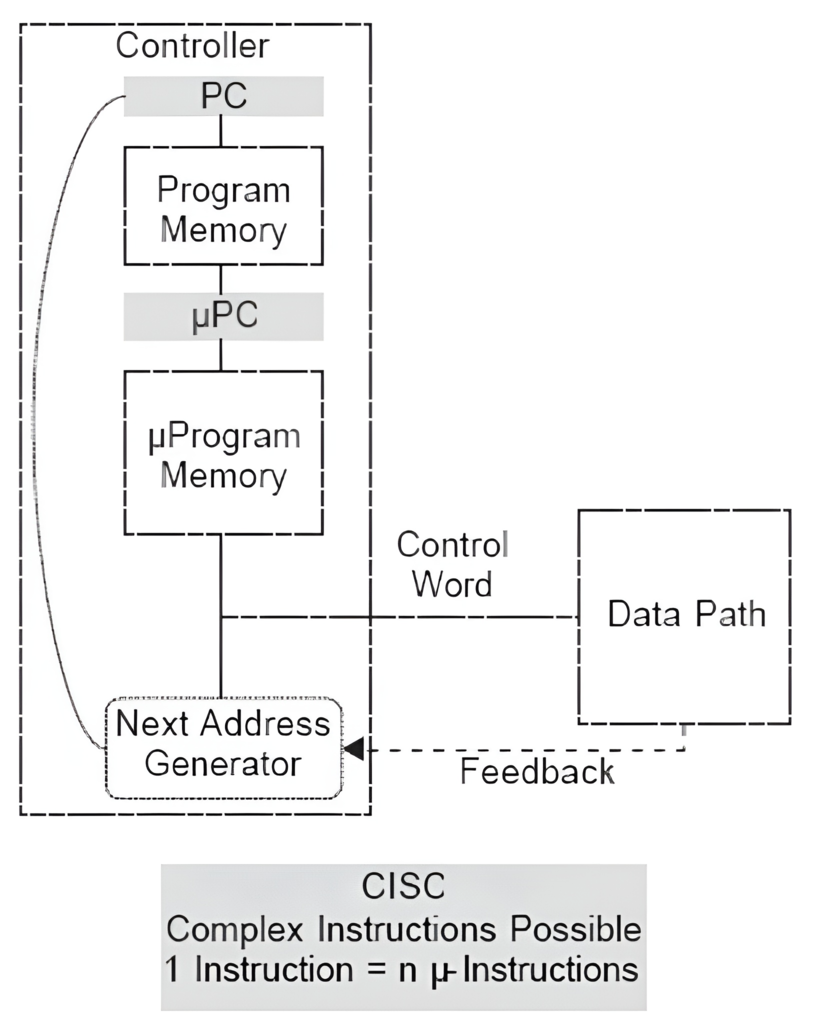 </div><div class="col"> А что если отказаться от системы команд и оставить только микрокод? 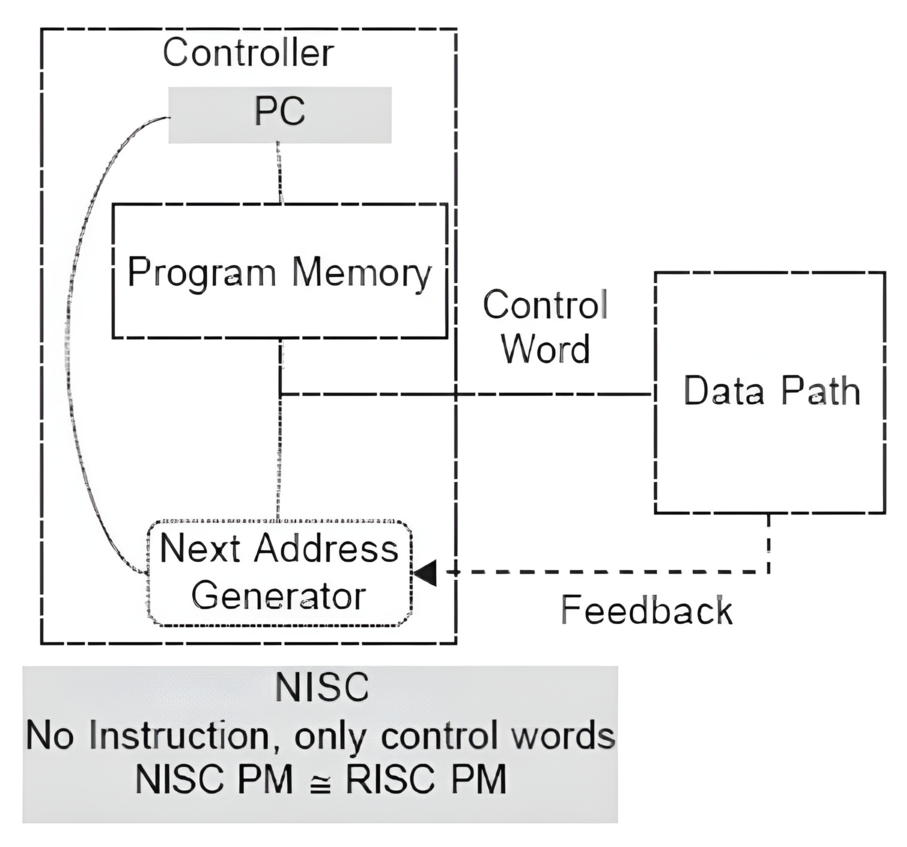 </div></div> ---- ##### Особенности NISC <div class="row"><div class="col"> Достоинства: 1. Упрощение аппаратуры. 1. Максимальная эффективность программного управления. 1. Нет ISA, нет проблем её проектирования. </div><div class="col"> Недостатки: 1. Невозможность бинарной совместимости. 1. Низкая плотность машинного кода. </div></div> Использование: 1. Применяется в ускорителях, в высокоуровневом синтезе (HLS), спец. вычислителях. 1. Проект [NITTA](https://ryukzak.github.io/projects/nitta/) — CGRA процессор, где вычислительные блоки управляются в стиле NISC. --- <div class="row"><div class="col"> ## Stack Machine ROSC — Reduced Operands Set Computer (скорее шутка) - Обработка данных не в регистрах, а на стеке. `mul`: - `a = pop(); b = pop()` - `c = a * b; push(c)` - Чтение `@` и запись `!` из/в память на/из стека. - Условные и безусловные переходы через стек: - если на стеке `0`: `PC = PC + 1` - иначе: `PC = CONST` - или иначе: `PC = pop()` - More: [Modern Stack Architecture](https://users.ece.cmu.edu/~koopman/forth/sdnc90b.pdf) [Stack Computers: the new wave](https://users.ece.cmu.edu/~koopman/stack_computers/index.html) ([ru](http://the-epic-file.com/text/bookz/sc/sc_contents.htm)) </div><div class="col"> 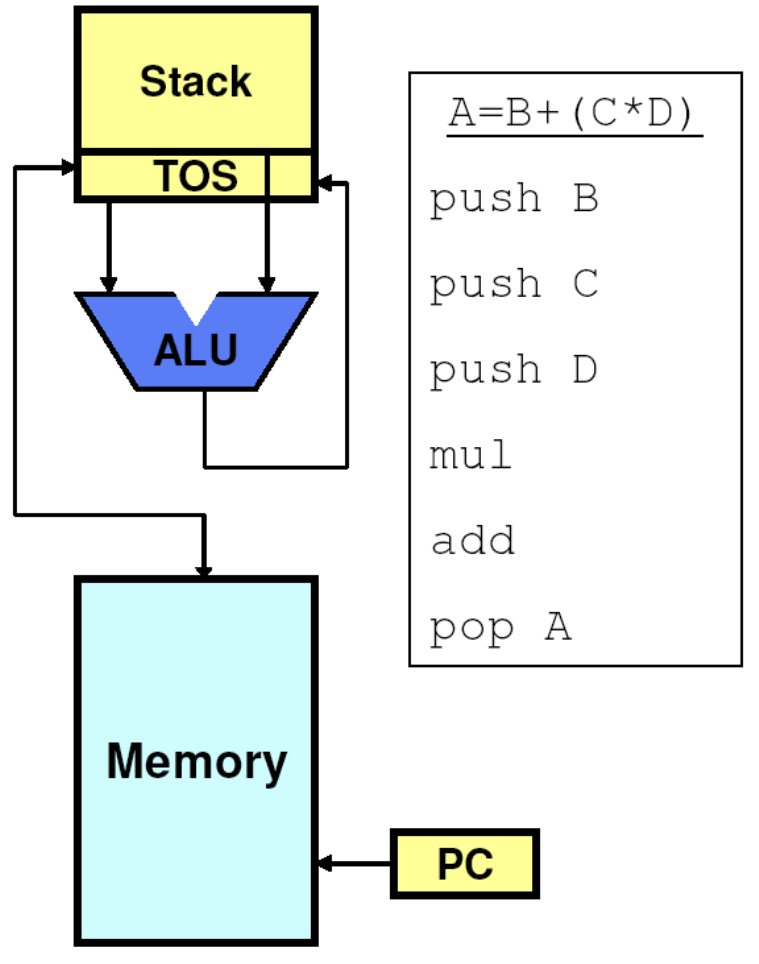 <!-- .element height="350px" --> 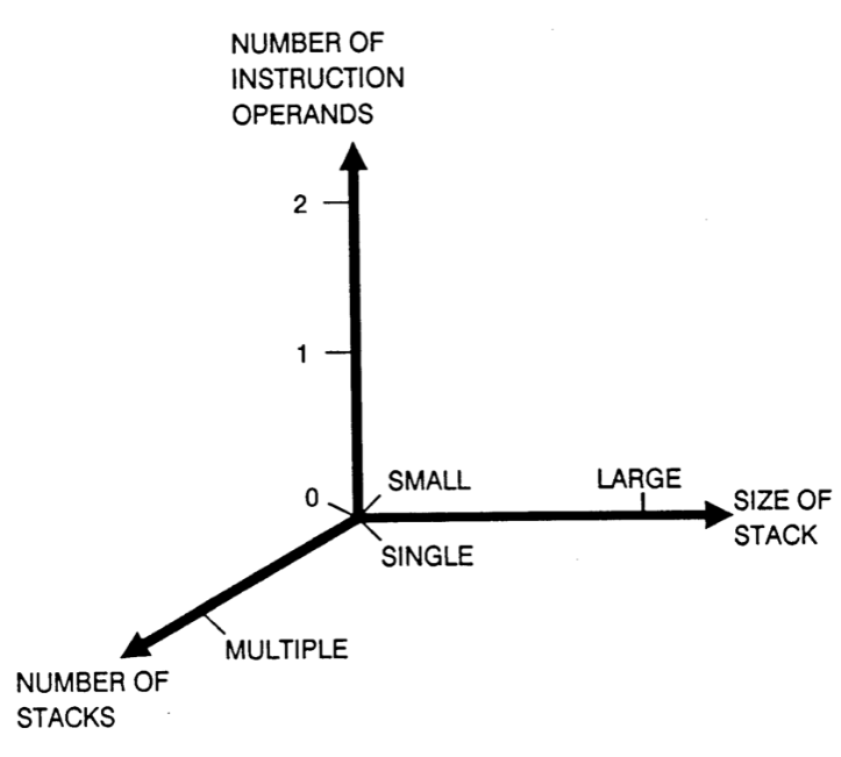 <!-- .element height="250" --> </div></div> ---- ### Forth (стековый язык программирования) <dl> <dt> Форт (англ. Forth) </dt> <dd> императивный язык программирования на основе стека. Особенности: структурное программирование, отражение (возможность исследовать и изменять структуру программы во время выполнения), последовательное программирование и расширяемость (новые команды). </dd> </dl> <div class="row"><div class="col"> ```forth : fac recursive dup 1 > IF dup 1 - fac * else drop 1 endif ; ``` </div><div class="col"> 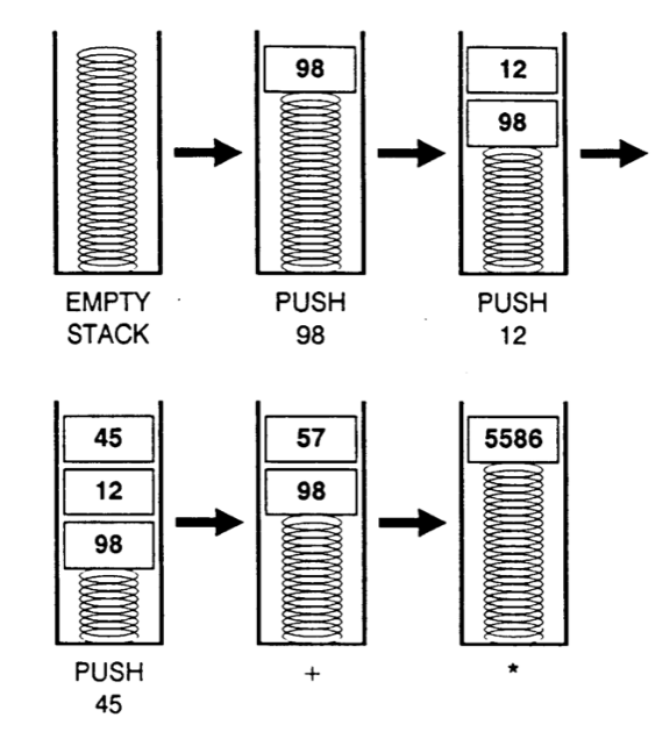 <!-- .element height="300" --> </div></div> ---- ```text data stack instruction frame [ ] 3 : Source code: [ 3 ] fac --------------------------> : [ 3 ] dup fac: : fac recursive [ 3 3 ] 1 fac: dup 1 > IF [ 3 3 1 ] > fac: dup 1 - fac * [ 3 t ] IF ------------------------> fac: ELSE [ 3 ] dup t:fac: drop 1 [ 3 3 ] 1 t:fac: ENDIF ; [ 3 3 1 ] - t:fac: [ 3 2 ] fac ---------------------> t:fac: 3 fac. [ 3 2 ] dup fac:t:fac: [ 3 2 2 ] 1 fac:t:fac: [ 3 2 2 1 ] > fac:t:fac: [ 3 2 t ] IF ------------------> fac:t:fac: [ 3 2 ] dup t:fac:t:fac: [ 3 2 2 ] 1 t:fac:t:fac: [ 3 2 2 1 ] - t:fac:t:fac: [ 3 2 1 ] fac ---------------> t:fac:t:fac: [ 3 2 1 ] dup fac:t:fac:t:fac: [ 3 2 1 1 ] 1 fac:t:fac:t:fac: [ 3 2 1 1 1 ] > fac:t:fac:t:fac: [ 3 2 1 f ] IF ------------> fac:t:fac:t:fac: [ 3 2 1 ] drop f:fac:t:fac:t:fac: [ 3 2 ] 1 f:fac:t:fac:t:fac: [ 3 2 1 ] ENDIF+RET <=== f:fac:t:fac:t:fac: [ 3 2 1 ] * t:fac:t:fac: [ 3 2 ] ENDIF+RET <========= f:fac:t:fac: [ 3 2 ] * t:fac: [ 6 ] ENDIF+RET <=== t:fac: [ 6 ] ``` ---- #### Особенности стековых процессоров <div class="row"><div class="col"> Достоинства: 1. High-level language computer architecture. - Процедуры. - Автоматическая память. - Рекурсия. - Выражения: `X=(A+B)*(C+D)` <br/> $\rightarrow$ `A B + C D + *` <br/> $\rightarrow$ `A B C D + + *` - Простой компилятор. 1. Простая система команд, высокая производительность. 1. Cache-friendly. 1. Threads. </div><div class="col"> Недостатки: - Эффективность при большом количестве данных на стеке. - Динамические структуры. - Параллелизм уровня инстр. - Сильно отличается.  <!-- .element height="300px" --> </div></div> ---- ### G144A12 <div class="row"><div class="col"> - F18A — асинхронный форт процессор. - G11A12 — multi-computer. - With 144 independent computers, it enables parallel or pipelined programming. - With instruction times as low as 1400 picoseconds and consuming as little as 7 picojoules of energy. - Частота исполнения инструкций порядка 700 MHz! - With completely programmable I/O pins. </div><div class="col"> Безумный стековый процессор из реального мира: [link](https://cyberleninka.ru/article/n/protsessory-greenarrays-ga144/pdf) 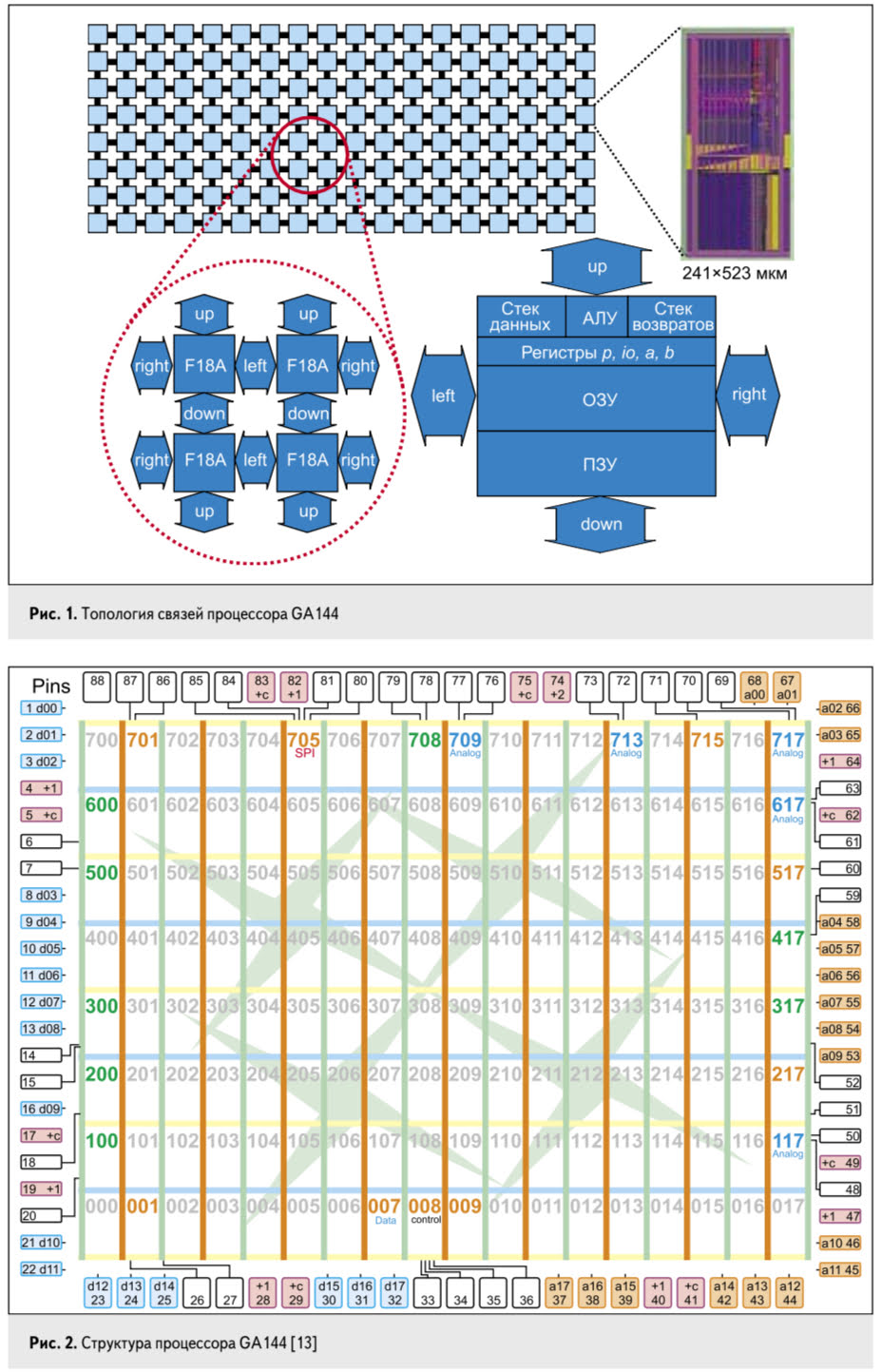 <!-- .element height="500px" --> </div></div> --- ### Источники роста производительности? <div> 1. Частота. 1. Специализация системы команд, аппаратуры. 1. Параллелизм уровня бит, инструкций, задач. 1. Адаптация структуры вычислителя под задачу и параллелизм. 1. Динамическая адаптация. </div> <!-- .element: class="fragment" --> -------------------------- #### И препятствия на его пути <div> <div class="row"><div class="col"> 1. Закон Мура 1. Закон Амдала 1. Закон Деннарда 1. Power Wall 1. Memory Wall </div><div class="col"> 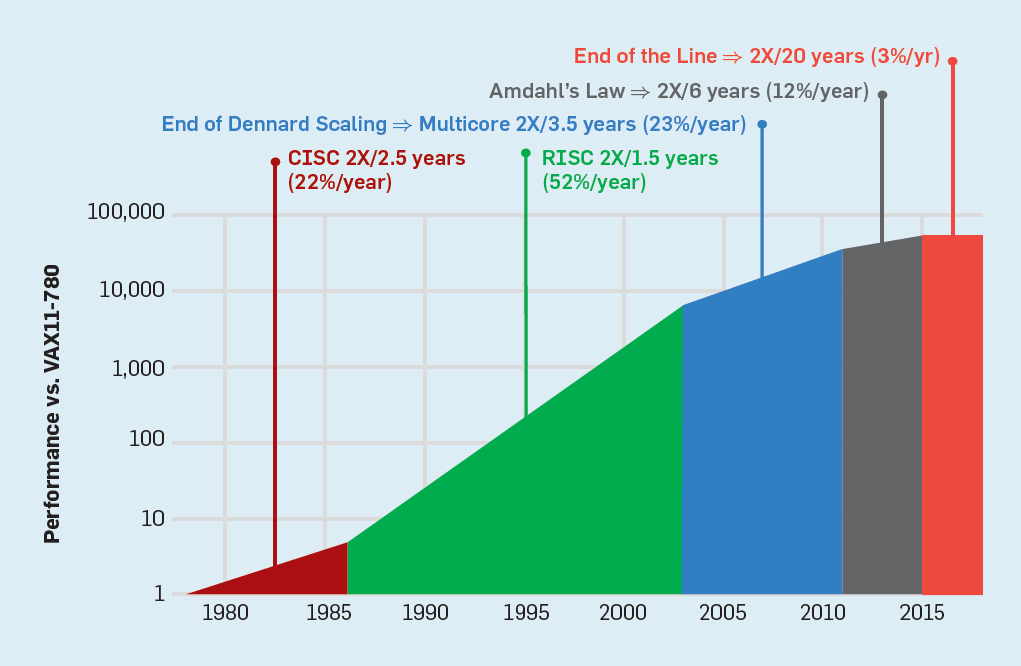 <!-- .element: height="250px" --> </div></div> </div> <!-- .element: class="fragment" --> ---- ### Закон Мура. Закон Амдала **Moore's law** is the observation that the number of transistors in a dense integrated circuit (IC) doubles about every two years. <div class="row"><div class="col"> 1. закон Амдала (фундаментальное ограничение на параллелизм) 1. накладные расходы на параллельные вычисления 1. объективная сложность параллельного программирования 1. доставка данных </div><div class="col"> 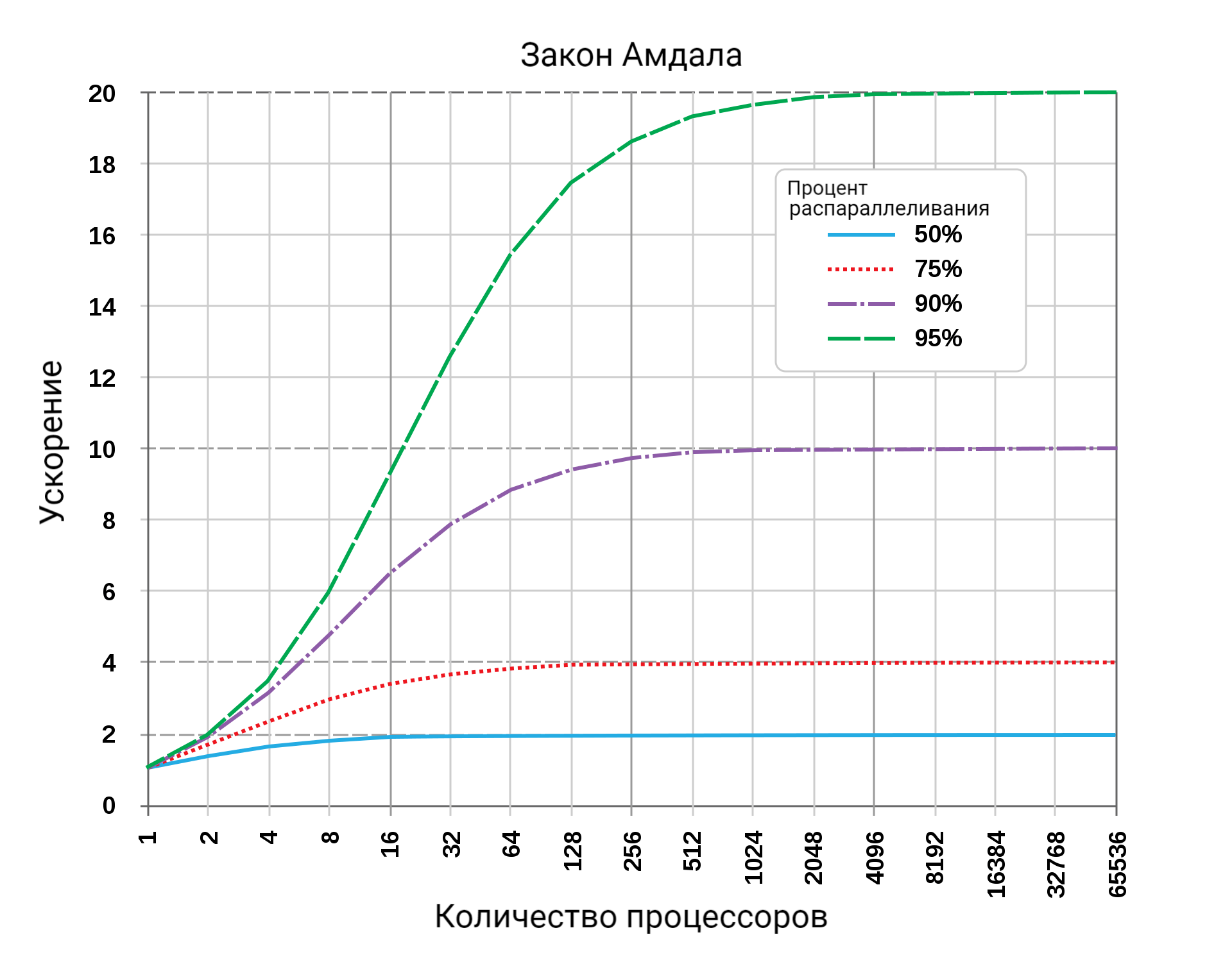 </div></div> ---- ### Закон Деннарда **Dennard scaling**, also known as MOSFET scaling, is a scaling law which states roughly that, as transistors get smaller, their power density stays constant, so that the power use stays in proportion with area; both voltage and current scale (downward) with length. <div class="row"><div class="col"> 1. Дороговизна (физическая невозможность) дальнейшего уменьшения размера транзистора. 1. Токи утечки. 1. Power wall и Dark Silicon $\longrightarrow$ </div><div class="col">  <!-- .element: height="250px" --> </div></div> ---- ### Power Wall. Dark Silicon 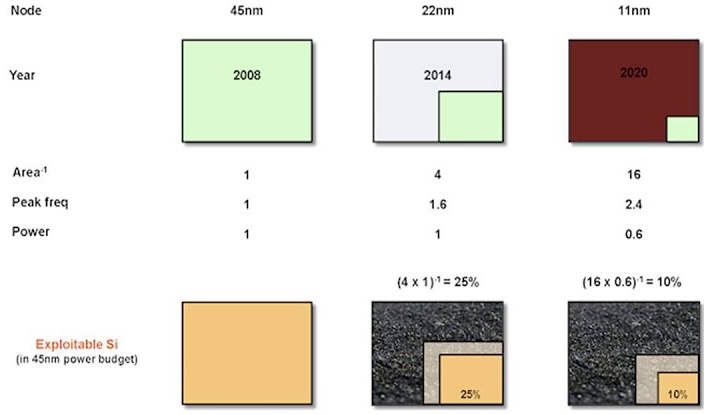 ---- #### Dark Silicon. Patterns 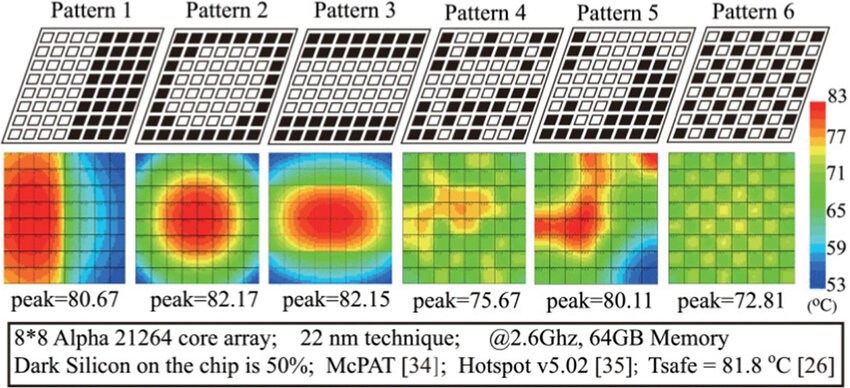 ---- ### Memory Wall. CPU vs. Memory Performance 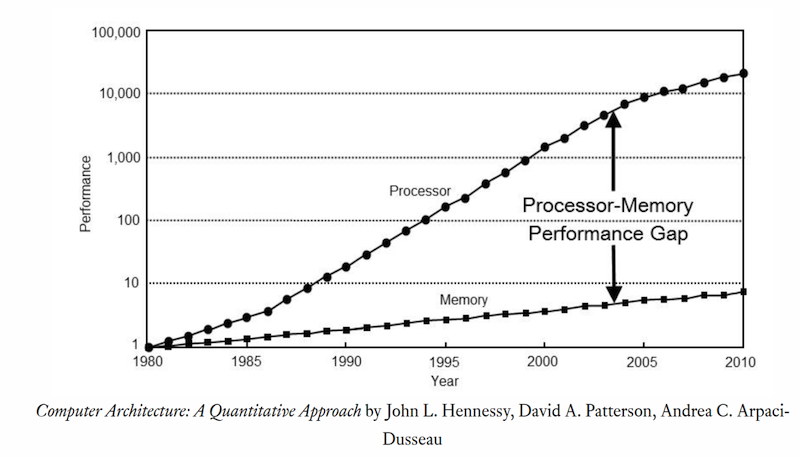 (относительные оценки) ---- ### Memory Wall. Artificial intelligence  Память в вычислителях vs. требуется для моделей. ---- 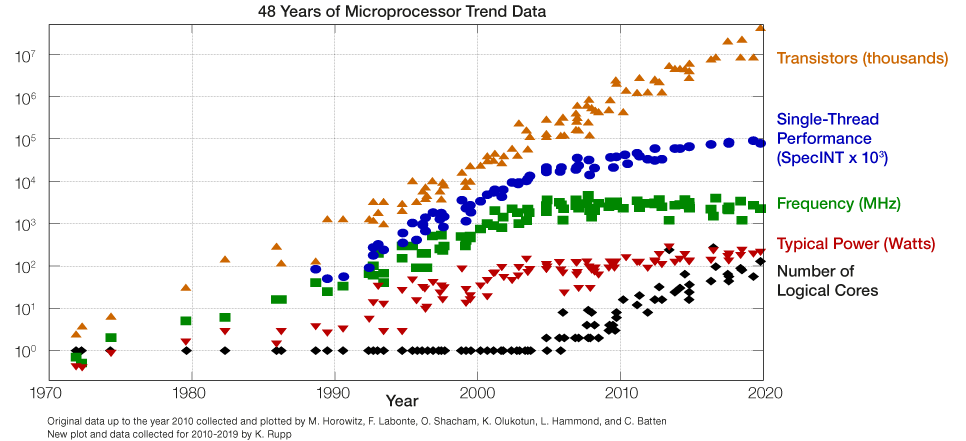 <!-- .element: height="250px" --> --- ## Reduced Instruction Set Computer <div class="row"><div class="col"> <dl> <dt> RISC </dt> <dd> подход к проектированию процессоров, где быстродействие увеличивается за счёт простого кодирования упрощённого набора инструкций. </dd> </dl> - Можем ли мы ускорить выполнение ограниченного количества инструкций? - Будет ли ограниченное число инструкций эффективнее? </div><div class="col"> 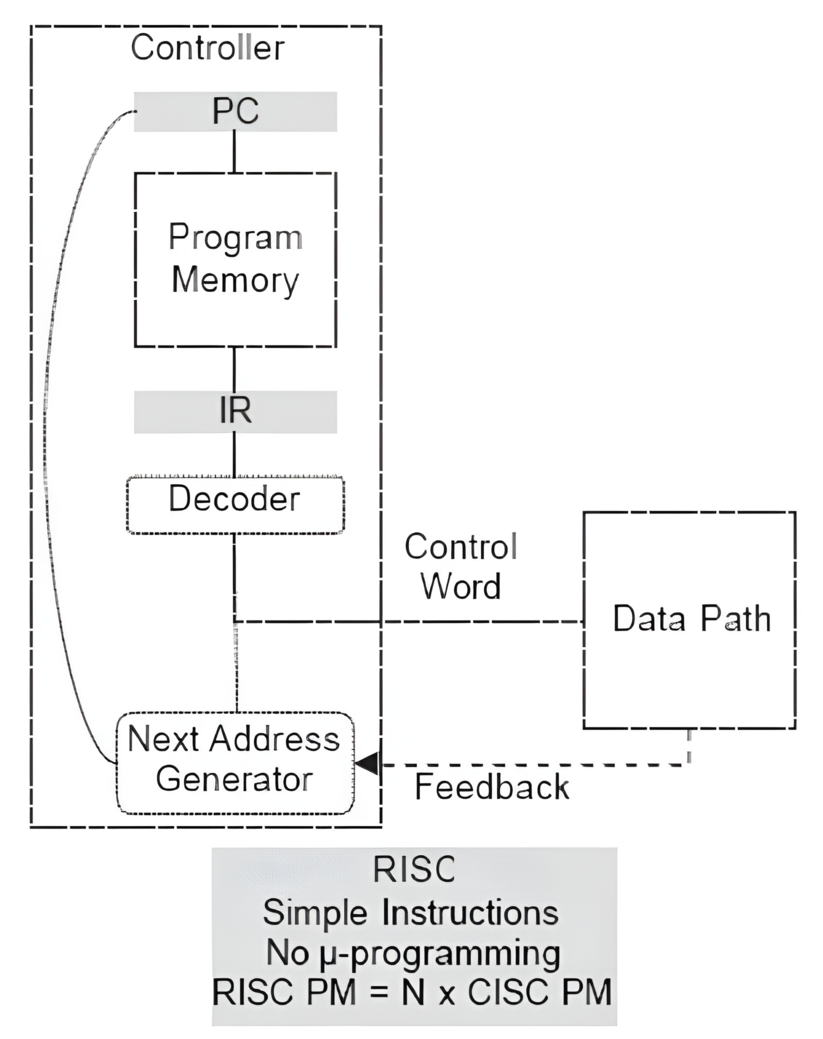 </div></div> ---- ### RISC. Предпосылки и особенности <div class="row"><div class="col"> 1. Сложные операции: - встречаются редко; - заменимы группами команд. 1. Появились ЯП высокого уровня. 1. Единый формат инструкций. Простота декодера инструкций. 1. Место памяти микрокоманд и декодера можно использовать для регистров и кеша. 1. Оптимизация малого количества однообразных команд. 1. Параллелизм уровня инструкций, pipeline. </div><div class="col"> 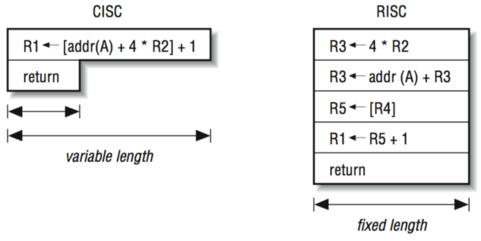 - "То, что раньше делали корпорации, теперь доступно для двух аспирантов". - Рост производительности "средней программы" за счёт ускорения частых инструкций. - Простой машинный код. </div></div> --- ### RISC. Pipeline. <br/> Параллелизм уровня инструкций  <!-- .element height="300px" --> 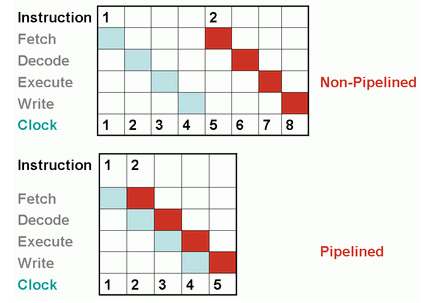 <!-- .element height="300px" --> Разбиваем обработку инструкции на несколько этапов и выполняем их параллельно для разных команд. Один такт — одна стадия конвейера. ---- #### Как построить конвейер? 1. выделить стадии выполнения команд; 2. организовать внутренние структуры процессора так, чтобы: - у процессора был входной (поступают команды) и выходной конец (команды "покидают" процессор); - структура процессора должна соответствовать стадиям выполнения команд; - сегменты связаны регистрами, комбинационные схемы сбалансированы; - все части процессора управляются одним тактовым сигналом; 3. загружать в процессор команды каждый такт; 4. получать результаты выполнения команд каждый такт; 5. разрешать конфликты параллельно выполняемых команд. ---- ### RISC. Типовые стадии конвейера <div class="row"><div class="col"> 1. **Instruction Fetch**. Чтение инструкции по счётчику команд. 2. **Instruction Decode**. Декодировать инструкцию и считать регистры. 3. **Instruction Execute**. Операций изменения данных. 4. **Memory Access**. Чтение/запись операндов из памяти/в память. 5. **Write Back**. Запись результата в регистры. </div><div class="col"> 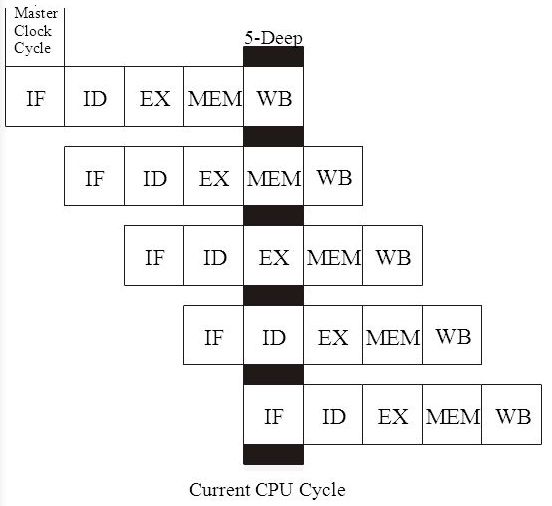 <!-- .element height="350px" --> <small> - Операции: - Register-Register (Single-cycle latency): Сложение, вычитание, сравнение и логические операции. - Memory Reference (Two-cycle latency): Подготовка адресов для доступа к памяти. - Multi-cycle (Many cycle latency): Целочисленное умножение, деление и все операции с плавающей запятой. </small> </div></div> ---- ### RISC. Типовая организация  --- ### RISC. Проблемы конвейеризации (Всё ведь не может быть так хорошо?) - Структурные конфликты / Structural dependency - Конфликты по данным / Data Dependency / Data Hazard - Конфликты по управлению / Control Dependency / Branch Hazards ---- #### Структурные конфликты / Structural Dependency - Конфликт из-за ресурсов. Аппаратура не позволяет выполнить все возможные комбинации инструкций. - Пример: одновременный доступ к единой памяти команд/данных. ```text | Tick | 1 | 2 | 3 | 4 | 5 | | Instr. | | | | | | |---------|------|------|------|-------|-------| | I1 | *IF* | ID | EX | *Mem* | WB | | I2 | | *IF* | ID | EX | *Mem* | | I3 | | | *IF* | ID | EX | | I4 | | | | *IF* | ID | | I5 | | | | ^ | *IF* | | ^ | | Write Back Conflict ---+ | Memory Access | Execution | Instruction Decode | Instruction Fetch ``` - Варианты полного решения проблемы: - Гарвардская архитектура. - Двухпортовая память. ---- #### Разрешение конфликта пузырьком ```text | Tick | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | | Instr. | | | | | | | | | | |---------|------|------|------|-------|-------|-------|---------|----|----| | I1 | *IF* | ID | EX | *Mem* | WB | | | | | | I2 | | *IF* | ID | EX | *Mem* | WB | | | | | I3 | | | *IF* | ID | EX | *Mem* | WB | | | | - | | | | 0 | 0 | 0 | 0 | 0 | | | - | | | | ^ | 0 | 0 | 0 | 0 | 0 | | - | | | | | | ^ | 0 | 0 | 0 | 0 | | I4 | | | | | | | | ^ | *IF* | ID | EX | | | | | | | push bubbles ---+-------+-------+ ``` - `0` — пузырёк: - занимает конвейер; - не выполняет никаких действий; - просто в реализации; - снижение эффективности. --- #### Конфликты по данным (Hazards) <div class="row"><div class="col"> ##### RAW: Read after Write <br/> (Data-dependency) ```asm and r1 <- __ & __ sub __ <- r1 - __ ```  </div><div class="col"> ##### WAR: Write after Read <br/> (Anti-dependency) ```asm and __ <- r1 & __ sub r1 <- __ - __ ; problem for reordering ``` ##### WAW: Write after Write <br/> (Output dependency) ```asm and r1 <- __ & __ sub r1 <- __ - __ ; problem with caches ``` ##### RAR: (Read after Read) ```asm and __ <- R1 & __ sub __ <- R1 - __ ; not a problem ``` </div></div> ---- ##### RAW — Read after Write (Data-dependency) ```asm and r1 <- __ + __ sub __ <- r1 - __ ``` ```text | Tick | 1 | 2 | 3 | 4 | 5 | 6 | | Stage | | | | | | | |-------|-----|-----|-------|-------|-------|-----| | IF | and | sub | | | | | | ID | | and | sub | | | | | EX | | | and | | sub | | | | MEM | | | | | | and | | sub | | | WB | | | | | | | | and | sub | | | | | 1. exec --+ | | | | | +---- 2.write 3. read --+ | ^ ^ +-- 4. exec | | | | CONFLICT | +--------------------------+ ``` ---- #### Механизмы разрешения Data Hazard 1. Исполнения не по порядку (out-of-order). Компилятор/процессор. ```text i1. R3 <- __ - __ i1. R3 <- __ - __ i2. __ <- R3 + __ => i3. __ <- __ + __ i3. __ <- __ + __ i4. __ <- __ + __ i4. __ <- __ + __ i2. __ <- R3 + __ ``` 1. Переименования регистров. Если зависимость по данным ложная. Запись может быть переназначена на другой регистр (пример WAW). 1. Вставка пузырька. 1. Проброс операндов (bypassing, operand forwarding) между стадиями процессора, минуя регистровый файл. ---- <div class="row"><div class="col"> ##### Проброс операндов <br/> (Bypassing, Operand Forwarding)  - Запись в регистр `i1:WR` - Подмена операнда в `i2:EX` - Проброс значения осуществляется без регистров $\longrightarrow$ в один такт. </div><div class="col"> ##### Bypassing + Bubble   </div></div> --- #### Конфликты по управлению <br/> (Control Dependency, Branch Hazards) - Конфликт из-за операций условного и/или безусловного перехода. - Проблема: в конвейер загружены команды, которые не должны быть исполнены. <div class="row"><div class="col"> Решения: - bubble, - сброс конвейера, - минимизация количества [условных] переходов, - loop unrolling, - условное перемещение данных, - предсказание переходов (branch prediction). </div><div class="col">  </div></div> --- ### Branch Prediction #### Статические предсказания переходов Предсказание определяется инструкцией перехода.  1. Условный переход **вперёд** — не произойдёт. 1. Условный переход **назад** — произойдёт (циклы). 1. Некоторые процессоры (Pentium 4) поддерживают "подсказки компилятора" для предсказаний. ---- #### Динамические предсказания переходов Предсказание использует историю переходов программы.  <!-- .element height="260px" -->  <!-- .element height="260px" --> Счётчик с накоплением, 2-bit  ---- ##### Многоуровневые предсказатели переходов <div class="row"><div class="col"> Проблема: у условного перехода есть периодичность (`11101110...`). </div><div class="col"> ```c for (int i = 0; i < 3; ++i) // code here. ``` </div></div> - Correlation-Based Branch Predictor - Branch History — Local (specific branch) or Global (all branches) - Table sizes. Branch Address collisions. Processes and Threads. - Больше деталей: <https://danluu.com/branch-prediction> 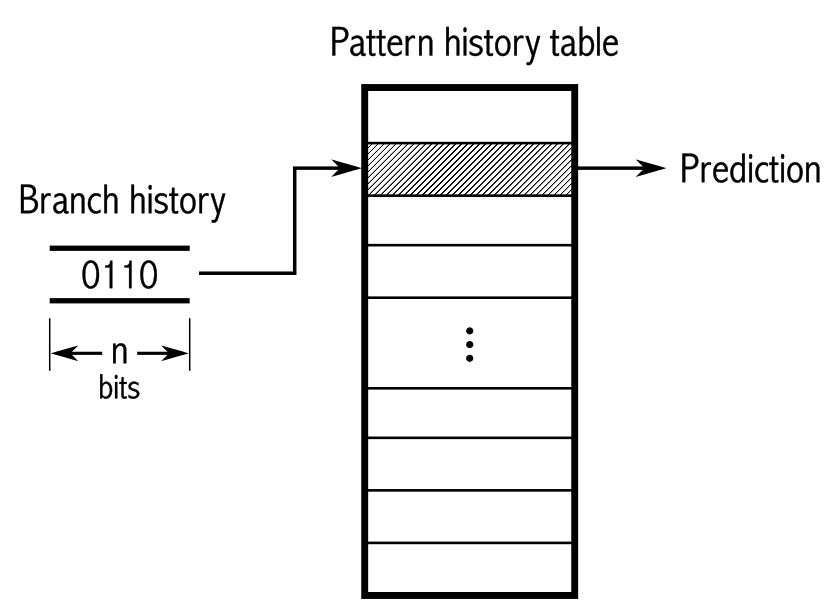 <!-- .element height="300px" --> 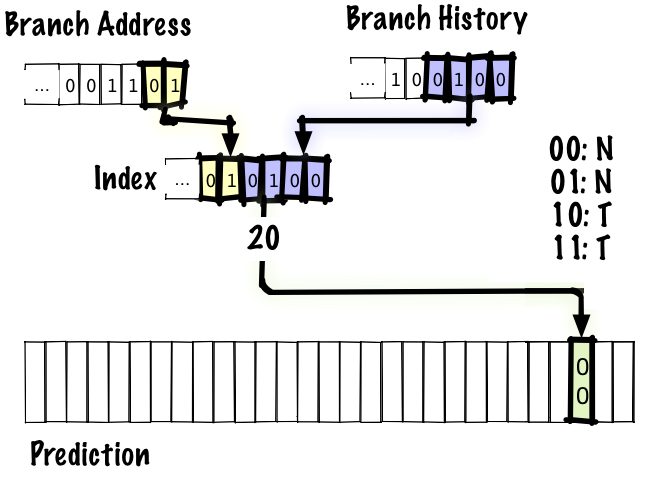 <!-- .element height="300px" --> --- ### Branch Prediction. Практика ```c++ const unsigned arraySize = 32768; int data[arraySize]; for (unsigned c = 0; c < arraySize; ++c) { data[c] = std::rand() % 256; } #ifdef SORT_DATA std::sort(data, data + arraySize); #endif long long sum = 0; for (unsigned i = 0; i < 100000; ++i) { for (unsigned c = 0; c < arraySize; ++c) { if (data[c] >= 128) sum += data[c]; } } ``` Полный код: [src/branch_prediction.cpp](https://gitlab.se.ifmo.ru/computer-systems/csa-rolling/-/blob/master/src/branch_prediction.cpp) На сколько будет отличаться время работы для сортированного и несортированного массивов? ---- | `branch_prediction_unsorted-O0` | `branch_prediction_sorted-O0` | | ------------------------------- | ----------------------------- | | Elapsed time: 19.5104 | Elapsed time: 3.83967 | | Sum: 312426300000 | Sum: 312426300000 | -------------------- - Оптимизация отключена `-O0` - Скорость работы на несортированном массиве низкая, так как предсказатель переходов часто ошибается. - Скорость работы на сортированном массиве высокая, так как предсказатель переходов не ошибается. - Подробнее: [Why is processing a sorted array faster than processing an unsorted array?](https://stackoverflow.com/questions/11227809/why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array) ---- #### Branch Prediction. Практика. Оптимизация | `branch_prediction_unsorted-O3` | `branch_prediction_sorted-O3` | |---------------------------------|--------------------------| | Elapsed time: 1.95652 | Elapsed time: 1.95178 | | Sum: 312426300000 | Sum: 312426300000 | -------------------- - Оптимизация включена `-O3` - if-statement заменяется на инструкцию условной пересылки `cmov`. - Условие не выполнится — пересылка данных не произойдет. - `cmov` не требует сброса конвейера при невыполнении условия. <div class="row"><div class="col"> `-O0` ```asm cmp data[j], 128 jl .if_end mov eax, j mov ecx, eax mov rcx, data[rcx] add sum, rcx ``` </div><div class="col"> `-O3` ```asm cmp edx, 127 cmovle edx, r15d ;r15d always equals 0 add rbx, edx ;rbx = sum ``` </div></div> ---- ##### Разворачивание циклов (Loop Unrolling) <div class="row"><div class="col"> это техника трансформации циклов, которая помогает оптимизировать время выполнения программы за счёт уменьшения количества итераций. Разворачивание циклов увеличивает скорость программы за счет устранения инструкций управления циклом и инструкций проверки цикла. </div><div class="col"> ```c for (int x = 0; x < 100; x++) { delete(x); } ``` $\downarrow$ ```c for (int x = 0; x < 100; x += 5 ) { delete(x); delete(x + 1); delete(x + 2); delete(x + 3); delete(x + 4); } ``` </div></div> ---- #### Количество сброшенных инструкций 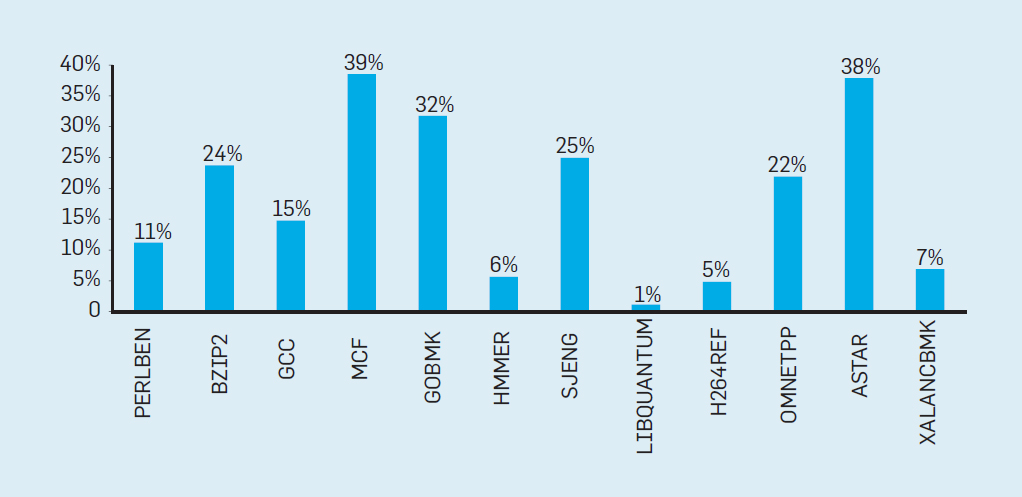 Процессор — Core i7 --- ### Конвейер. Практика PIC — 2; Core i7 — 14; Pentium 4 — 20; Xeon — 30; <br/> Xelerated X10q Network Processor — 200 стадий. Преимущества: - повышение производительности и уровня утилизации ресурсов. Недостатки/проблемы: - снижение скорости исполнения отдельной команды; - не все операции за один машинный цикл; - необходимость разрешения конфликтов; - непредсказуемое время исполнения; - уязвимости "косвенных каналов" ([Meltdown](https://en.wikipedia.org/wiki/Meltdown_(security_vulnerability)), [Spectre](https://en.wikipedia.org/wiki/Spectre_(security_vulnerability))); - как быть с виртуальными методами? ---- ### RISC. Практика <div class="row"><div class="col"> Почему RISC не победил CISC? Или победил? <div> - Мобильные — уже. ПК и сервера — в процессе. - Инструментальная поддержка (сколько лет делали `clang`?). - Бинарная совместимость (виртуализация, аппаратная трансляция, транспиляция). - Зависимость себестоимости от серийности. - RISC ядро внутри CISC. </div> <!-- .element: class="fragment" --> </div><div class="col">  </div></div> --- <div class="row"><div class="col"> **Краткая выжимка**: ```asm ;;;; Acc load ACC <- A ; acc mul ACC <-* B ; 1 operands add ACC <-+ C store Y <- ACC ``` ```asm ;;;; CISC mul R1 <- A * B ; reg-to-mem add Y <- R1 + C ; 2 operands ;; or mul D <- A * B ; mem-to-mem add Y <- D + C ; 2 operands ``` ```asm ;;;; RISC load R1 <- A ; reg-to-reg load R2 <- X ; 2 operands load R3 <- B mul R4 <- R1 * R2 add R5 <- R4 + R3 store Y <- R5 ``` ```forth \\\\ Stack A @ B @ * \ stack, 0 operands C @ + Y ! \ @ - read, ! - write ``` </div><div class="col"> - Acc. Через аккумулятор: - ариф. операции, ввод-вывод. - 1 оп. — явный, 2 — неявный. - CISC. Сложные инструкции. - Переменная длина. - Спец. регистры. - Ариф. операции и доступ(-ы) в память за одну инструкцию. - RISC. Простые инструкции. - Единый размер инструкций. - Операции и работа с памятью — разные инструкции. - Регистры — одинаковые. - Stack. Через стек: - Ариф. операции, ввод-вывод. - Операнды — неявные (часто). </div></div> Notes: зависит от алгоритма, неплохо бы оптимизировать под задачу.