# Архитектура компьютера ## Лекция 8 ## Память инструкций и данных. Принципы DataPath. <br/> CISC. Микрокод Пенской А.В., 2026 --- ### Память инструкций и данных. <br/> Принстонская и Гарвардская архитектуры <div class="row"><div class="col"> **Принстонская архитектура (фон Неймановская)**. Узкое место — совместная память: - доступ к инструкциям и данным - по очереди по одному каналу. </div><div class="col"> **Гарвардская архитектура**. Памяти разделены: - память инструкций и память данных — разные устройства, - каналы инструкций и данных физически разделены. </div></div>  ---- #### Гарвардская архитектура. Особенности ##### Достоинства 1. Два физических канала между процессором и памятью. 1. Одновременный доступ к памяти. 1. Разная ширина машинного слова и адреса для данных и программ. - Оптимизация под решаемую задачу. 1. Изоляция памяти инструкций. ##### Недостатки 1. Сложность и стоимость реализации. 1. Изоляция инструкций и данных: - Запуск результата компиляции. - Указатели на функции. *Вопрос*: От чего зависит размерность машинных слов <br/> и адресных пространств? ---- #### Вариации Гарвардской архитектуры <dl> <dt> Архитектура "Память инструкций как данные" <br/> (Instruction-memory-as-data) </dt> <dd> реализуется возможность читать и писать данные в память программ. Позволяет генерировать и запускать машинный код. </dd> </dl> -------------------- <dl> <dt> Архитектура "Память данных как инструкции" <br/> (Data-memory-as-instruction) </dt> <dd> реализует возможность запуска инструкций из памяти данных. Позволяет генерировать и запускать машинный код, но параллельный доступ ограничен. </dd> </dl> -------------------- <dl> <dt> Модифицированная Гарвардская архитектура (main stream) </dt> <dd> Доступ к памяти реализуется через независимые кеши для данных и программ, за счет чего, с точки зрения внутренней организации процессора, доступ реализован независимо, при этом канал между процессором и памятью один. </dd> </dl> --- ### Принцип работы с данными в DataPath 1. Accumulator Architectures 1. Register-to-Memory Architectures 1. Register-to-Register Architectures 1. Memory-to-Memory Architectures 1. Stack Architectures Источник: ECE C61 Computer Architecture Lecture 3 — Instruction Set ---- #### Accumulator Architectures 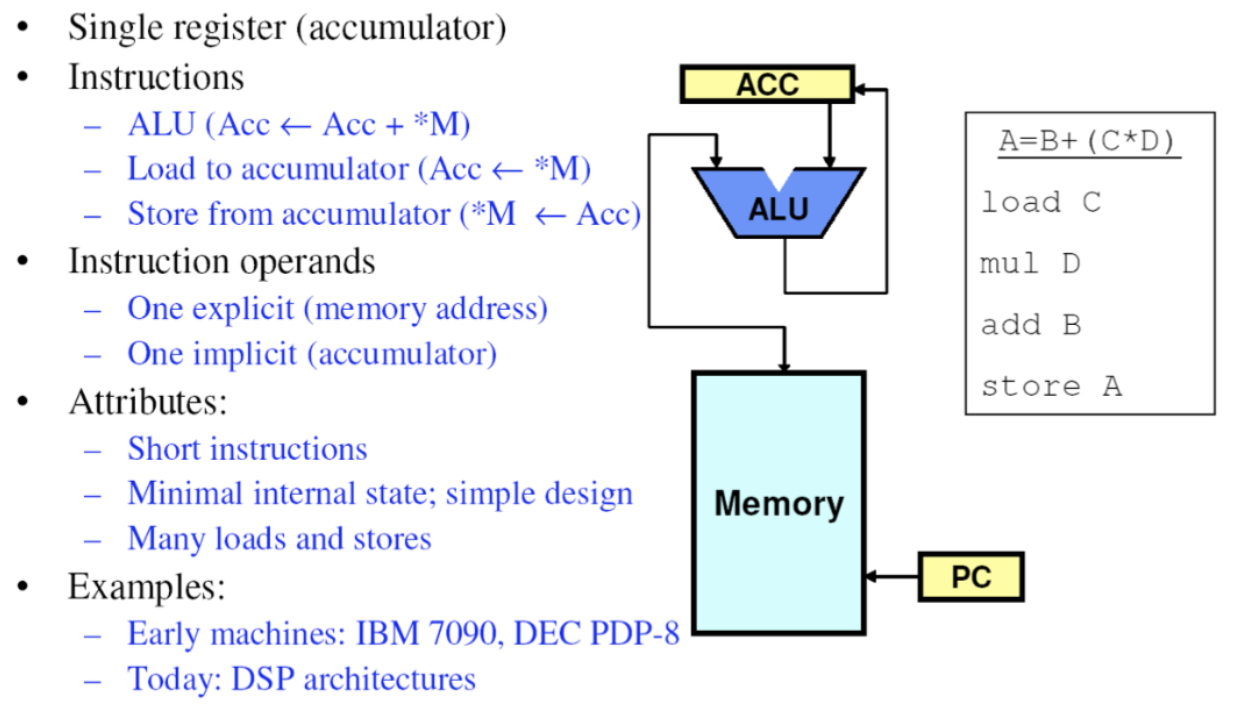 ---- #### Register-to-Memory Architectures 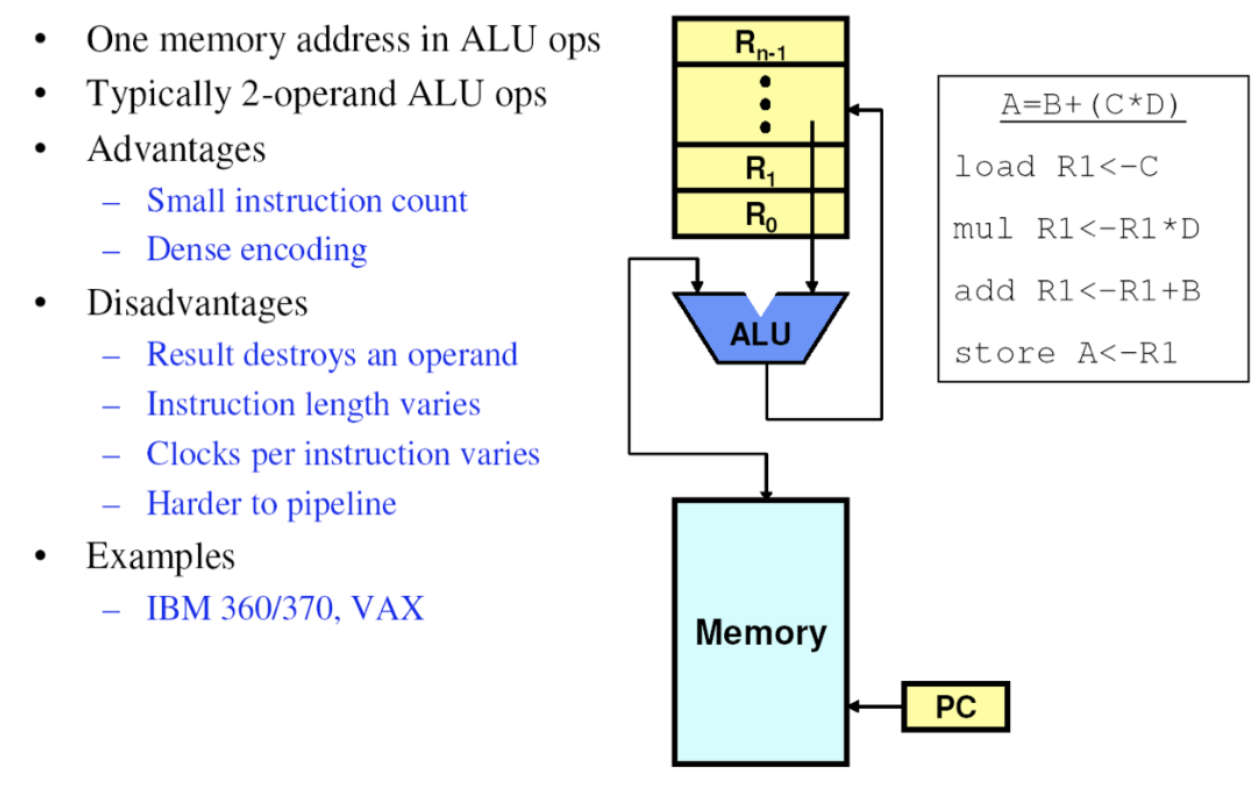 ---- #### Register-to-Register: Load-Store Architectures 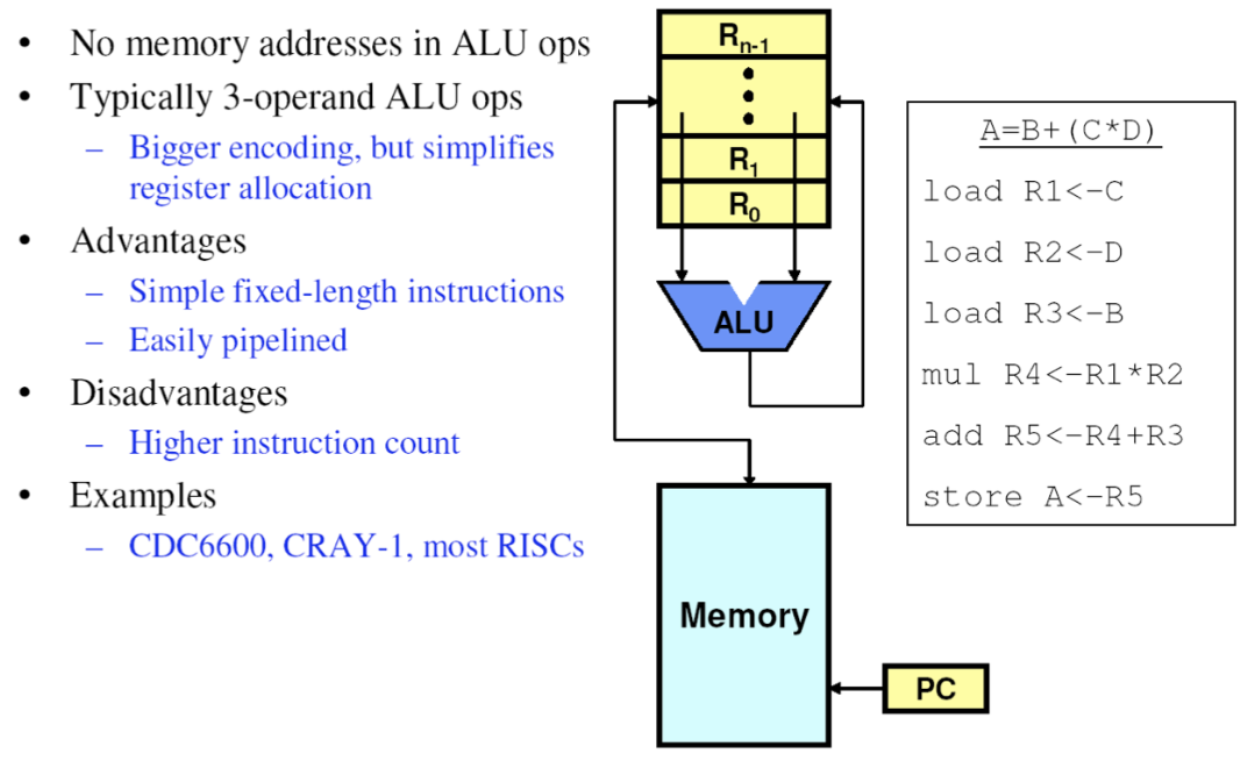 ---- #### Memory-to-Memory Architectures  ---- #### Stack Architectures 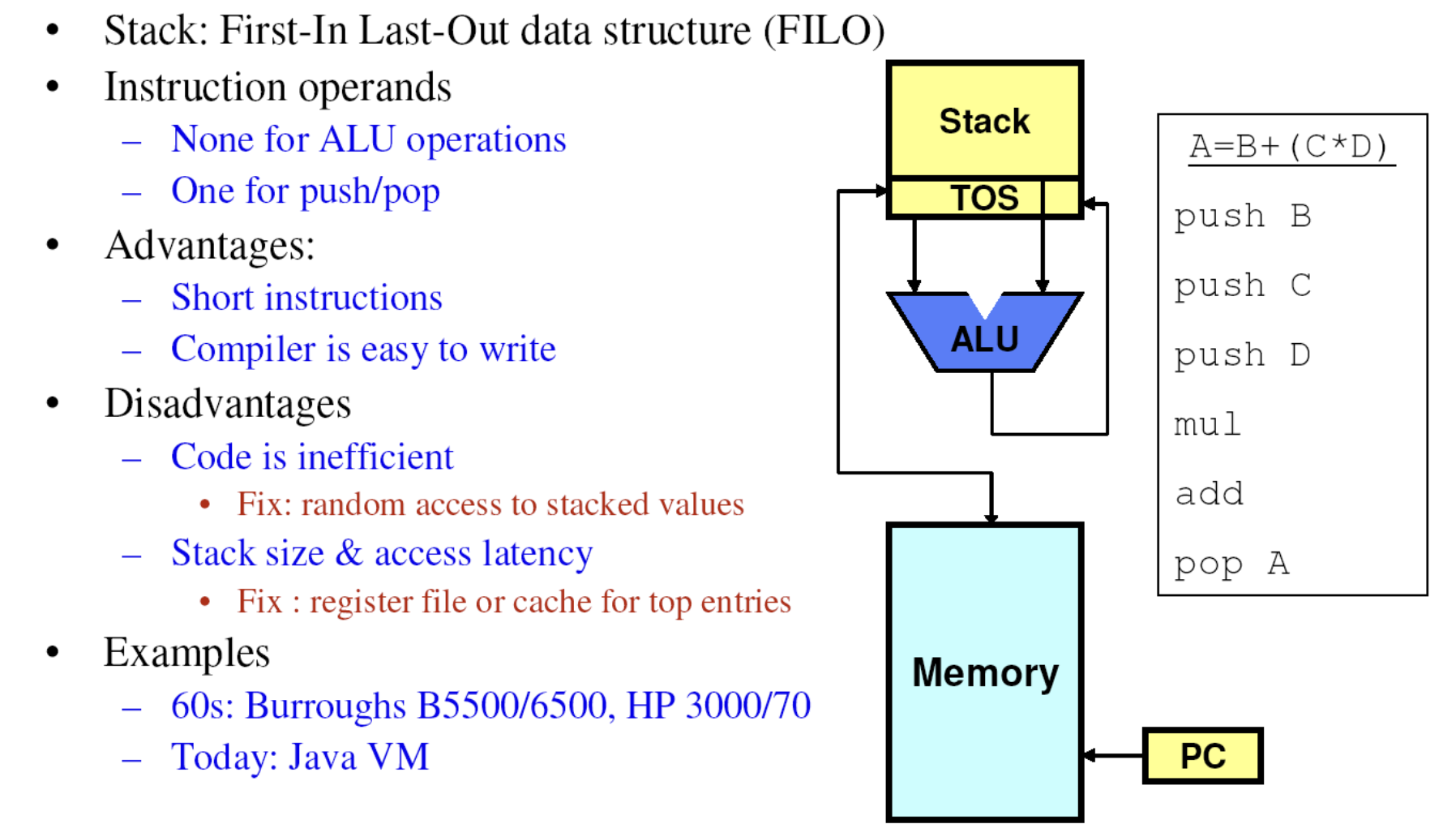 --- ### Система команд и линейная функция <div class="row"><div class="col"> ```asm load ACC <- A ; acc mul ACC <-* B ; 1 operands add ACC <-+ C store Y <- ACC ; (1) ``` ```asm load R1 <- A ; reg-to-mem mul R1 <- R1 * B ; 1 operands add R1 <- R1 + C store Y <- R1 ; (2) ``` ```asm load R1 <- A ; reg-to-reg load R2 <- X ; 2 operands load R3 <- B mul R4 <- R1 * R2 add R5 <- R4 + R3 store Y <- R5 ; (3) ``` ```asm load R1 <- A ; reg-to-reg load R2 <- X ; 3 operands load R3 <- B lnf R4 <- R1 * R2 + R3 store Y <- R4 ; (4) ``` </div><div class="col"> $Y = A * X + B$ ```asm mul R1 <- A * B ; reg-to-mem add Y <- R1 + C ; 2 operands (5) ``` ```asm lfn Y <- A * B + C ; mem-to-mem ; 3 operands (6) ``` ```forth A @ B @ * \ stack, 0 operands (7) C @ + Y ! \ @ - read, ! - write ``` Что лучше? - (1) — начало - CISC (2, 4, 5, 6) - RISC (3) - Stack (7) </div></div> Notes: зависит от алгоритма, неплохо бы оптимизировать под задачу. --- ## Машина фон Неймана. Пример <br/> Accumulator Architectures 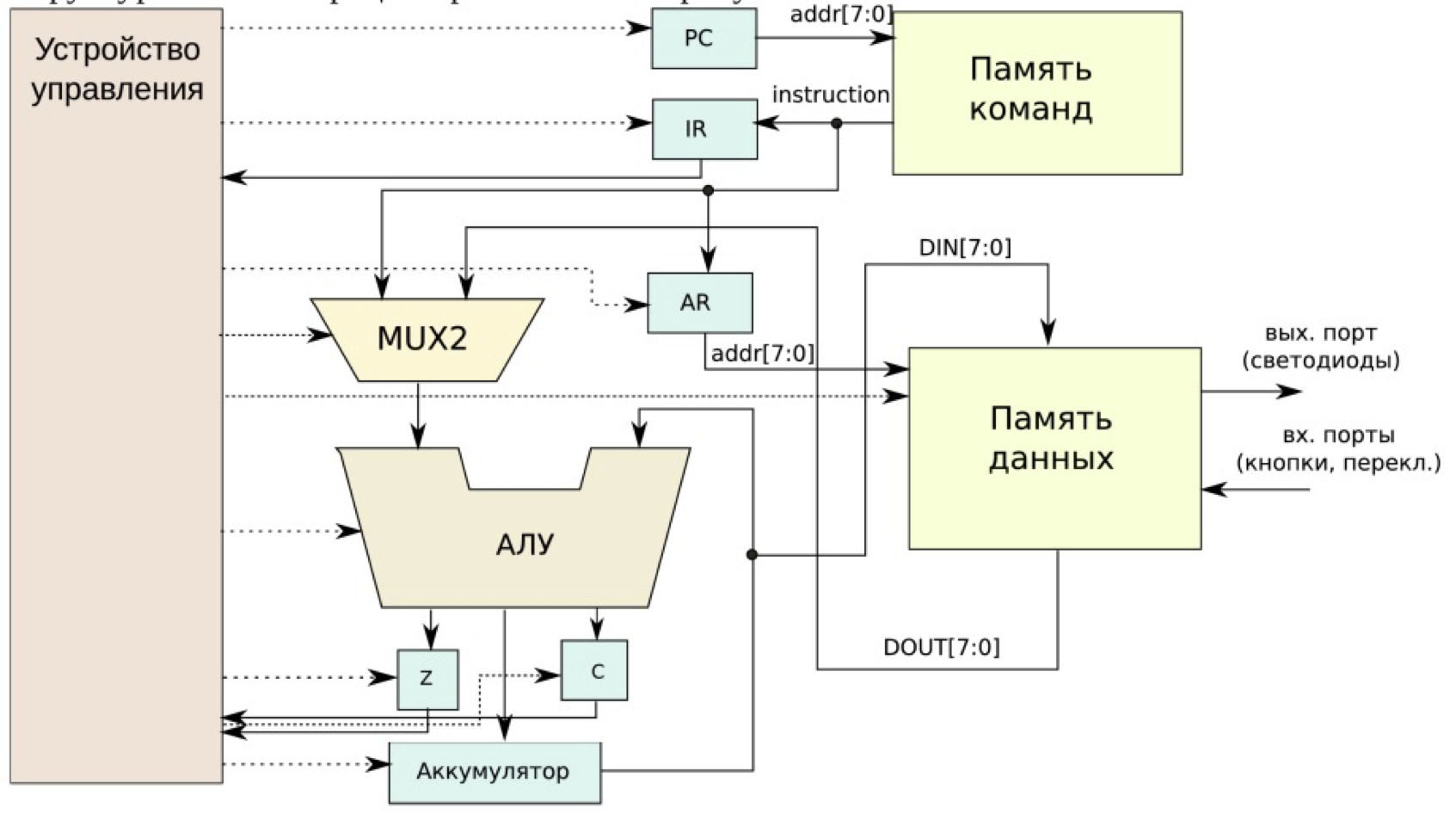 ---- <div class="row"><div class="col"> ### Характеристики  - Регистры и флаги: - `PC` — счетчик команд - `IR` — регистр инструкций - `AR` — регистр адреса операнда - `C` — флаг переноса/займа - `Z` — флаг нуля </div><div class="col"> - Разрядность процессора: 8 бит. - Организация памяти: Гарвардская. - Внешние устройства отображаются в адресное пространство данных. Работа по опросу. - Команды выполняются за 2 или 3 такта: - Выборка команды. - Выборка операндов. - Выполнение команды. - Прерывания и команды вызова подпрограмм отсутствуют. [Пример модели процессора на Haskell](http://amazing-new-gate.blogspot.com/2010/07/haskell.html) </div></div> ---- ### Пример исполнения инструкции <div class="row"><div class="col">  ```asm add #01 <- 34 + #03 ; [ <opcode>, 34, 03, 01 ] 5t acc <- 34 ; [ <opcode>, 34 ] 2t acc <-+ #03 ; [ <opcode>, 03 ] 3t #01 <- Acc ; [ <opcode>, 01 ] 3t ``` 1. Реальное устройство DataPath может не соответствовать ISA. 1. Сложные инстр. эффективнее. </div><div class="col"> ```asm ;--------- 1. Чтение инструкции IR <- PMem[PC] PC <- PC+1 ;--------- 2. Инициализация акк. 34 { Acc, Z, C } <- ALU(...) <- MUX2(...) <- PMem[PC] PC <- PC+1 ;--------- 3. Выгрузка адреса 03 AR <- PMem[PC] PC <- PC+1 ;--------- 4. Выгрузка адреса 01 ;--------- Выгрузка #03 и сложение AR <- PMem[PC] { Acc, Z, C } <- ALU(...) <- MUX2(...) <- DMem[AR].DOUT PC <- PC+1 ;--------- 5. Сохранение результата DMem[AR].DIN <- Acc ``` </div></div> --- ## Complex Instruction Set Computer <dl> <dt> CISC (Complex Instruction Set Computer) </dt> <dd> архитектура процессора, в которой одна инструкция может выполнять несколько низкоуровневых операций (загрузка из памяти, арифметика, запись в память) или использовать сложные многошаговые режимы адресации в рамках одной инструкции. </dd> </dl> <div class="row"><div class="col"> Причины появления: - Низкоуровневые языки. - Разнообразие архитектур. - Неразвитость компиляторов. - Удобство программирования. - Высокая производительность. - Минимизация объёма программ. - Минимизация накладных расходов. </div><div class="col"> Проблемы: - Сложная система команд (использование, анализ). - Сложное устройство процессора и Control Unit. - Сложно генерировать эффективный машинный код. </div></div> ---- ### Подходы к реализации Control Unit <div class="row"><div class="col"> <dl> <dt> Hardwired </dt> <dd> при помощи аппаратных комбинационных схем, декодирующих инструкции в последовательности сигналов. </dd> </dl> <dl> <dt> Microcoded </dt> <dd> при помощи исполнения микропрограммы, реализующей необходимые функции. </dd> </dl> <dl> <dt> Микропрограмма (микрокод) </dt> <dd> программа, реализующая набор инструкций процессора. </dd> </dl> </div><div class="col">  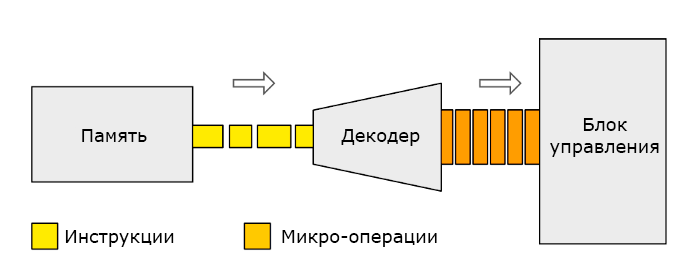 </div></div> ---- <div class="row"><div class="col"> #### Микропрограммное управление. Пример /1 1. Выделяем сигналы управления: - защёлкивание регистров; - чтение/запись в память; - селекторы мультиплексоров. 2. Создаём память микрокоманд. Ширина слова соответствует количеству сигналов. 3. Определяем микрокоманды для поиска начала инструкций (`00-01`). 4. Реализуем механизм поиска `n1`. 5. Пишем микрокод для инструкций (`n1-n4`), завершаем их `mjmp 00`. </div><div class="col"> ```text 00 01 ... n1 n2 n3 n4 latch_PC 1 0 ... 1 1 1 0 mux_PC +1 0 ... +1 +1 +1 0 latch_IR 1 0 ... 0 0 0 0 latch_AR 0 0 ... 0 1 1 0 MUX2 0 0 ... PM 0 DM 0 ALU 0 0 ... +0 0 +A 0 OE 0 0 ... 0 0 1 0 WR 0 0 ... 0 0 0 1 latch_mPC 1 1 ... 1 1 1 1 mux_mPC +1 DC ... +1 +1 +1 =0 | +-- mpc <- decoder(IR) ```  </div></div> ---- <div class="row"><div class="col"> #### Микропрограммное управление. Пример /2 ```asm add #01 <- 34 + #03 ;--------- 1. Чтение инструкции IR <- PMem[PC] PC <- PC+1 ;--------- 2. Инициализация акк. 34 { Acc, Z, C } <- ALU(...) <- MUX2(...) <- PMem[PC] PC <- PC+1 ;--------- 3. Выгрузка адреса 03 AR <- PMem[PC] PC <- PC+1 ;--------- 4. Выгрузка адреса 01 ;--------- Выгрузка #03 и сложение AR <- PMem[PC] { Acc, Z, C } <- ALU(...) <- MUX2(...) <- DMem[AR].DOUT PC <- PC+1 ;--------- 5. Сохранение результата DMem[AR].DIN <- Acc ``` </div><div class="col"> ```text 00 01 ... n1 n2 n3 n4 latch_PC 1 0 ... 1 1 1 0 mux_PC +1 0 ... +1 +1 +1 0 latch_IR 1 0 ... 0 0 0 0 latch_AR 0 0 ... 0 1 1 0 MUX2 0 0 ... PM 0 DM 0 ALU 0 0 ... +0 0 +A 0 OE 0 0 ... 0 0 1 0 WR 0 0 ... 0 0 0 1 latch_mPC 1 1 ... 1 1 1 1 mux_mPC +1 DC ... +1 +1 +1 =0 | +-- mPC <- decoder(IR) ```  </div></div> ---- #### Поиск адреса микрокода для инструкции 1. **Алгоритмически**: сопоставление инструкции с условием + условный переход в рамках микропрограммы. 2. **Отображение кода операции на адрес микроинструкции** - **Прямое отображение** — opcode выступает в роли адресса. К примеру: opcode `0101` — `0x05` адрес микроинструкций. - **Непрямое отображение** — требует использования look-up-table для поиска нужного адреса (см. пример лаб. 4). ---- #### Микропрограммное управление <div class="row"><div class="col"> Достоинства: 1. Простота реализации сложных ISA (CISC). 2. "Программирование" системы команд. 3. Доступ к микрокоду для программиста. 4. Генерация ISA под задачу (сократить объём, повысить эффективность), см. [«Самсон»](https://www.computer-museum.ru/articles/sistemi_kompleksi/90/). </div><div class="col"> Недостатки: 1. Хранение микрокода в процессоре. 2. CISC долго учить. 3. Разнообразие архитектур $\rightarrow$ проблемы инструментария. 4. Разнообразие команд (форматы, размеры, длительности, доступ). Усложняет: - оптимизацию процессора; - инструментарий. 5. Микрокод привносит все проблемы программирования (сложность, отладка, методы). </div></div> --- #### No Instruction Set Computing (NISC) <div class="row"><div class="col"> 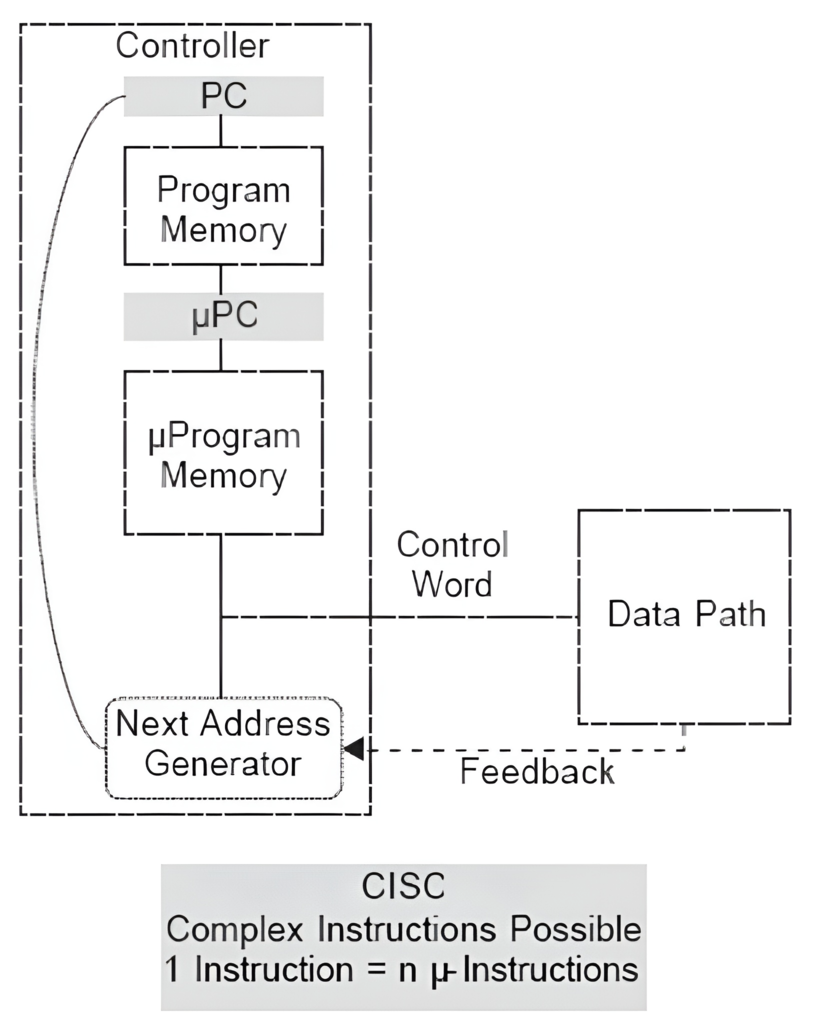 </div><div class="col"> А что если отказаться от системы команд и оставить только микрокод? 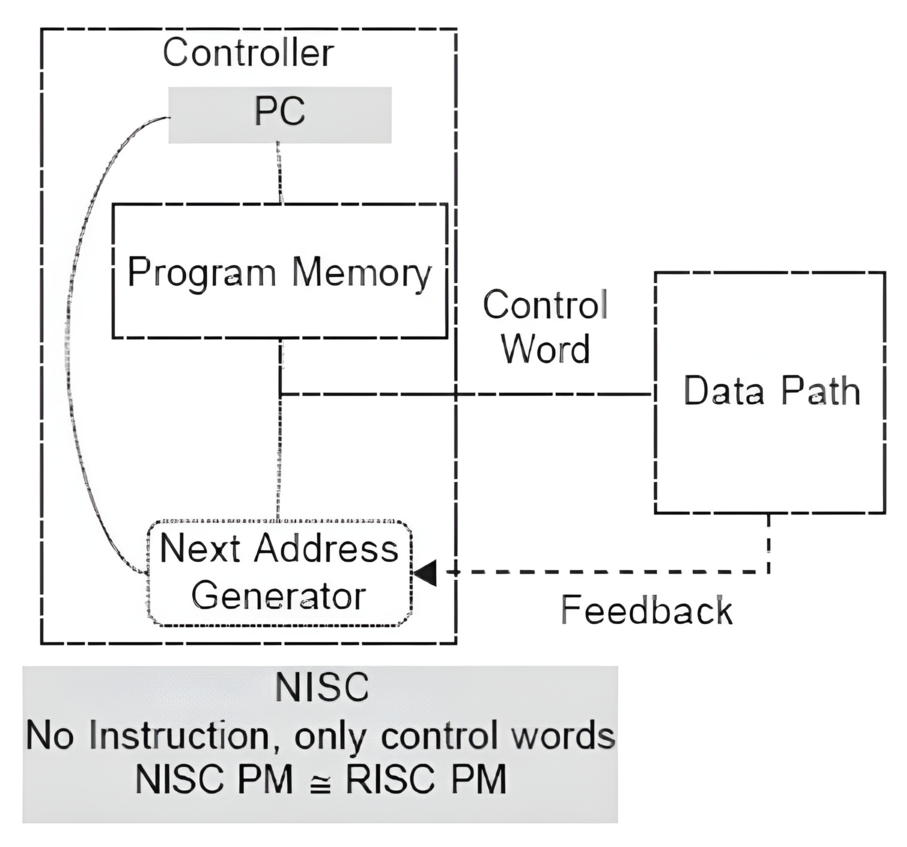 </div></div> ---- ##### Особенности NISC <div class="row"><div class="col"> Достоинства: 1. Упрощение аппаратуры. 1. Максимальная эффективность программного управления. 1. Нет ISA, нет проблем её проектирования. </div><div class="col"> Недостатки: 1. Невозможность бинарной совместимости. 1. Низкая плотность машинного кода. </div></div> Использование: 1. Применяется в ускорителях, в высокоуровневом синтезе (HLS), спец. вычислителях. 1. Проект [NITTA](https://ryukzak.github.io/projects/nitta/) — CGRA процессор, где вычислительные блоки управляются в стиле NISC: транслятор генерирует управляющие слова для каждого функционального блока напрямую, минуя традиционный уровень ISA.