# Архитектура компьютера ## Лекция 9 ## Stack. RISC Пенской А.В., 2026 --- <div class="row"><div class="col"> ## Stack Machine ROSC — Reduced Operands Set Computer (скорее шутка) 1. Обработка данных не в регистрах, а на стеке. `mul`: - `a = pop(); b = pop()` - `c = a * b; push(c)` 2. Чтение `@` и запись `!` из/в память на/из стека. 3. Условные и безусловные переходы через стек: - если на стеке `0`: `PC = PC + 1` - иначе: `PC = CONST` - или иначе: `PC = pop()` - More: [Modern Stack Architecture](https://users.ece.cmu.edu/~koopman/forth/sdnc90b.pdf) [Stack Computers: the new wave](https://users.ece.cmu.edu/~koopman/stack_computers/index.html) ([ru](http://the-epic-file.com/text/bookz/sc/sc_contents.htm)) </div><div class="col"> 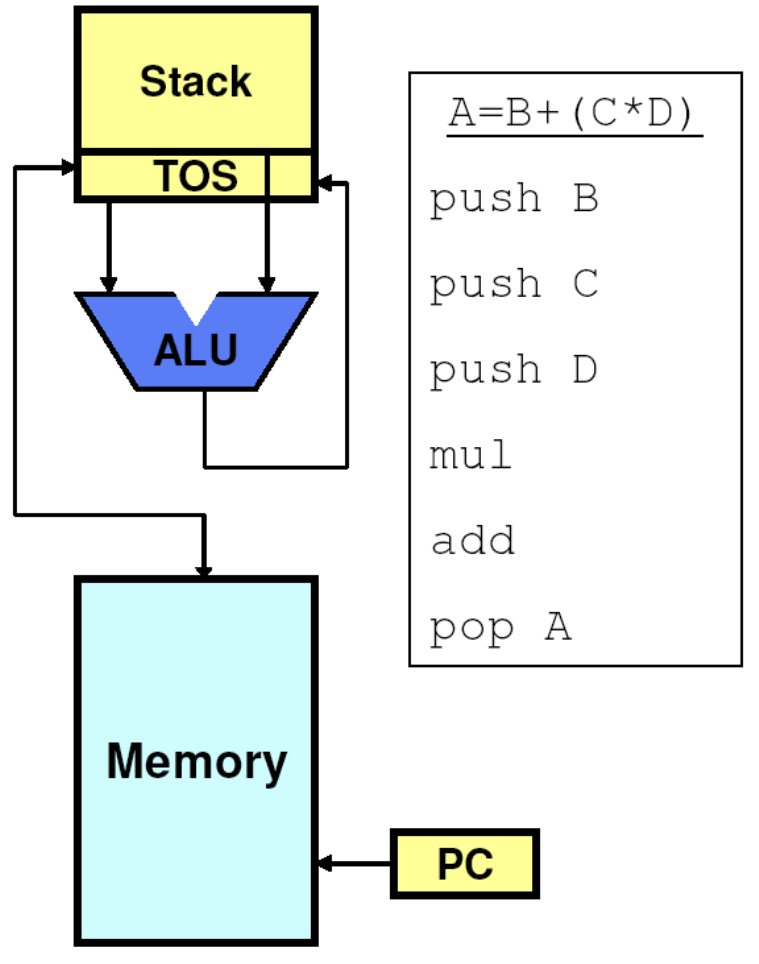 <!-- .element: height="350px" --> 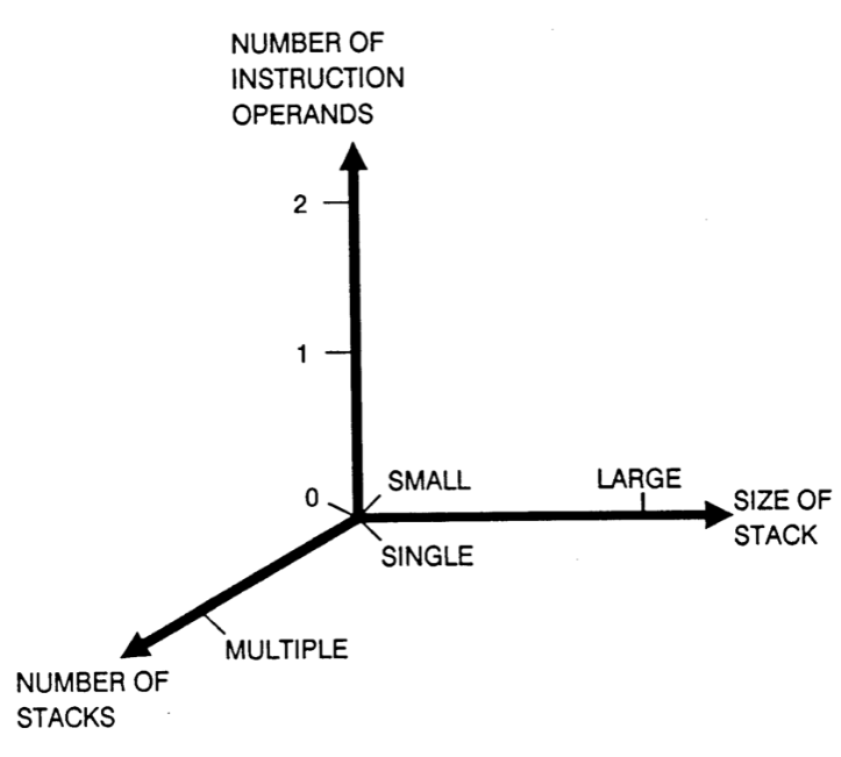 <!-- .element: height="250" --> </div></div> ---- ### Forth (стековый язык программирования) <dl> <dt> Форт (англ. Forth) </dt> <dd> императивный язык программирования на основе стека. Особенности: структурное программирование, отражение (возможность исследовать и изменять структуру программы во время выполнения), последовательное программирование и расширяемость (новые команды). </dd> </dl> <div class="row"><div class="col"> ```forth : fac recursive dup 1 > IF dup 1 - fac * else drop 1 endif ; ``` </div><div class="col"> 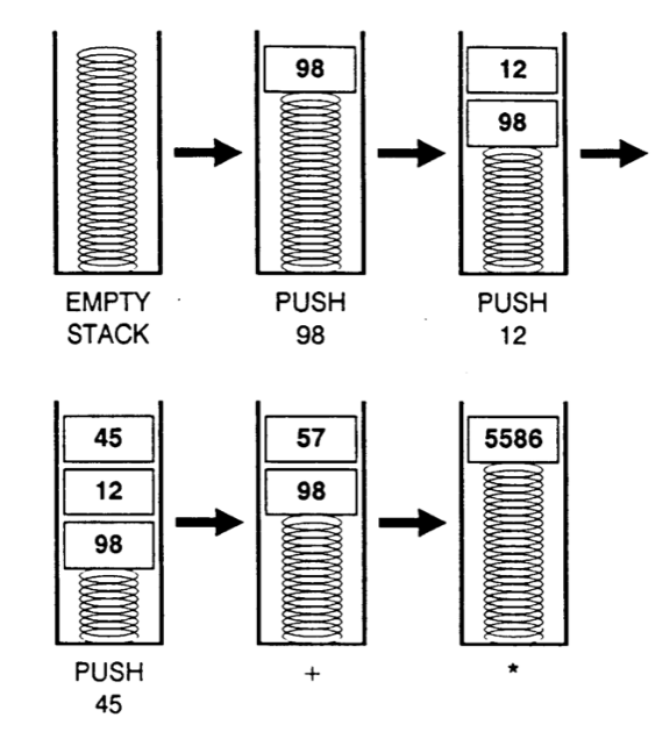 <!-- .element: height="300" --> </div></div> ---- Столбец `frame` — стек вызовов (глубина = число элементов, разделённых `:`). Стрелки `-->` обозначают вызов, `<===` — возврат. ```text data stack instruction frame [ ] 3 : Source code: [ 3 ] fac --------------------------> : [ 3 ] dup fac: : fac recursive [ 3 3 ] 1 fac: dup 1 > IF [ 3 3 1 ] > fac: dup 1 - fac * [ 3 t ] IF ------------------------> fac: ELSE [ 3 ] dup t:fac: drop 1 [ 3 3 ] 1 t:fac: ENDIF ; [ 3 3 1 ] - t:fac: [ 3 2 ] fac ---------------------> t:fac: 3 fac. [ 3 2 ] dup fac:t:fac: [ 3 2 2 ] 1 fac:t:fac: [ 3 2 2 1 ] > fac:t:fac: [ 3 2 t ] IF ------------------> fac:t:fac: [ 3 2 ] dup t:fac:t:fac: [ 3 2 2 ] 1 t:fac:t:fac: [ 3 2 2 1 ] - t:fac:t:fac: [ 3 2 1 ] fac ---------------> t:fac:t:fac: [ 3 2 1 ] dup fac:t:fac:t:fac: [ 3 2 1 1 ] 1 fac:t:fac:t:fac: [ 3 2 1 1 1 ] > fac:t:fac:t:fac: [ 3 2 1 f ] IF ------------> fac:t:fac:t:fac: [ 3 2 1 ] drop f:fac:t:fac:t:fac: [ 3 2 ] 1 f:fac:t:fac:t:fac: [ 3 2 1 ] ENDIF+RET <=== f:fac:t:fac:t:fac: ; fac(1)→1 [ 3 2 1 ] * t:fac:t:fac: [ 3 2 ] ENDIF+RET <========= f:fac:t:fac: ; fac(2)→2 [ 3 2 ] * t:fac: [ 6 ] ENDIF+RET <=== t:fac: ; fac(3)→6 [ 6 ] ``` ---- #### Особенности стековых процессоров <div class="row"><div class="col"> Достоинства: 1. High-level language computer architecture. - Процедуры. - Автоматическая память. - Рекурсия. - Выражения: `X=(A+B)*(C+D)` <br/> $\rightarrow$ `A B + C D + *` <br/> $\rightarrow$ `A B C D + + *` - Простой компилятор. 1. Простая система команд, высокая производительность. 1. Cache-friendly. 1. Threads. </div><div class="col"> Недостатки: 1. Эффективность при большом количестве данных на стеке. 1. Динамические структуры. 1. Параллелизм уровня инструкций. 1. Непривычная модель программирования (сильно отличается от регистровых архитектур).  <!-- .element: height="300px" --> </div></div> ---- ### G144A12 <div class="row"><div class="col"> 1. F18A — асинхронный форт процессор. 1. G11A12 — multi-computer. 1. With 144 independent computers, it enables parallel or pipelined programming. 1. With instruction times as low as 1400 picoseconds and consuming as little as 7 picojoules of energy. - Частота исполнения инструкций порядка 700 MHz! 1. With completely programmable I/O pins. </div><div class="col"> Безумный стековый процессор из реального мира: [link](https://cyberleninka.ru/article/n/protsessory-greenarrays-ga144/pdf) 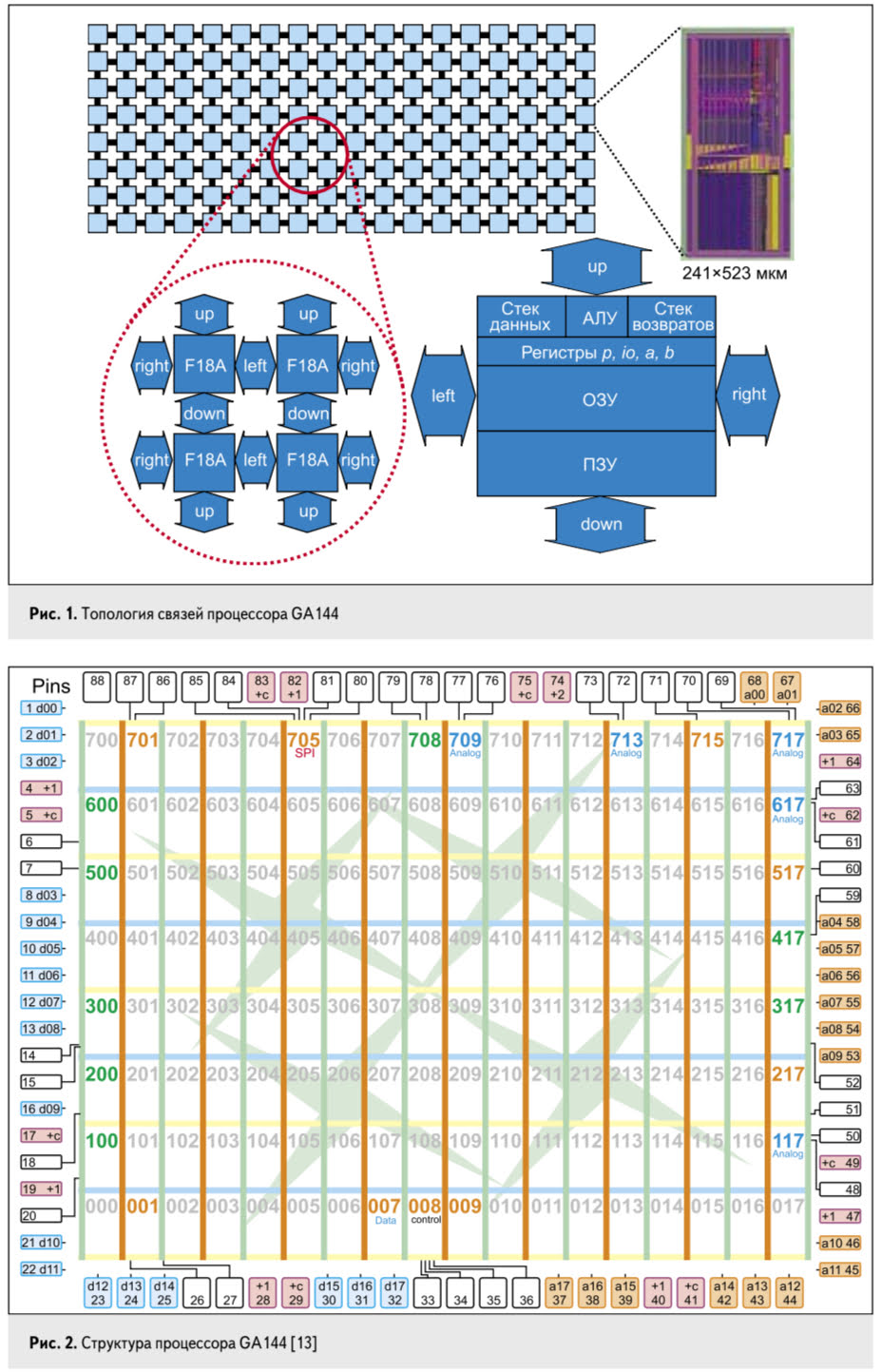 <!-- .element: height="500px" --> </div></div> --- ### Стековые процессоры: итог - Стековые машины занимают свою нишу во встраиваемых и специализированных системах. - Прежде чем перейти к RISC — рассмотрим фундаментальные ограничения роста производительности, с которыми сталкиваются все архитектуры. --- ### Источники роста производительности? <div> 1. Частота. 1. Специализация системы команд, аппаратуры. 1. Параллелизм уровня бит, инструкций, задач. 1. Адаптация структуры вычислителя под задачу и параллелизм. 1. Динамическая адаптация. </div> <!-- .element: class="fragment" --> -------------------------- #### И препятствия на его пути <div> <div class="row"><div class="col"> 1. Закон Мура 1. Закон Амдала 1. Закон Деннарда 1. Power Wall 1. Memory Wall </div><div class="col">  <!-- .element: height="250px" --> </div></div> </div> <!-- .element: class="fragment" --> ---- ### Закон Мура. Закон Амдала **Moore's law** is the observation that the number of transistors in a dense integrated circuit (IC) doubles about every two years. <div class="row"><div class="col"> 1. закон Амдала (фундаментальное ограничение на параллелизм) 1. накладные расходы на параллельные вычисления 1. объективная сложность параллельного программирования 1. доставка данных </div><div class="col">  </div></div> ---- ### Закон Деннарда **Dennard scaling**, also known as MOSFET scaling, is a scaling law which states roughly that, as transistors get smaller, their power density stays constant, so that the power use stays in proportion with area; both voltage and current scale (downward) with length. <div class="row"><div class="col"> 1. Дороговизна (физическая невозможность) дальнейшего уменьшения размера транзистора. 1. Токи утечки. 1. Power wall и Dark Silicon $\longrightarrow$ </div><div class="col">  <!-- .element: height="250px" --> </div></div> ---- ### Power Wall. Dark Silicon  ---- #### Dark Silicon. Patterns  ---- ### Memory Wall. CPU vs. Memory Performance 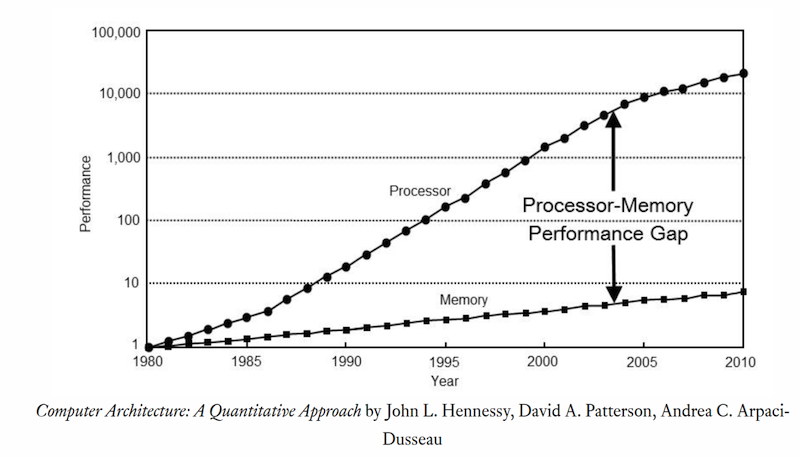 (относительные оценки) ---- ### Memory Wall. Artificial intelligence  Объём доступной памяти в вычислителях vs. объём, требуемый для моделей ИИ. ---- 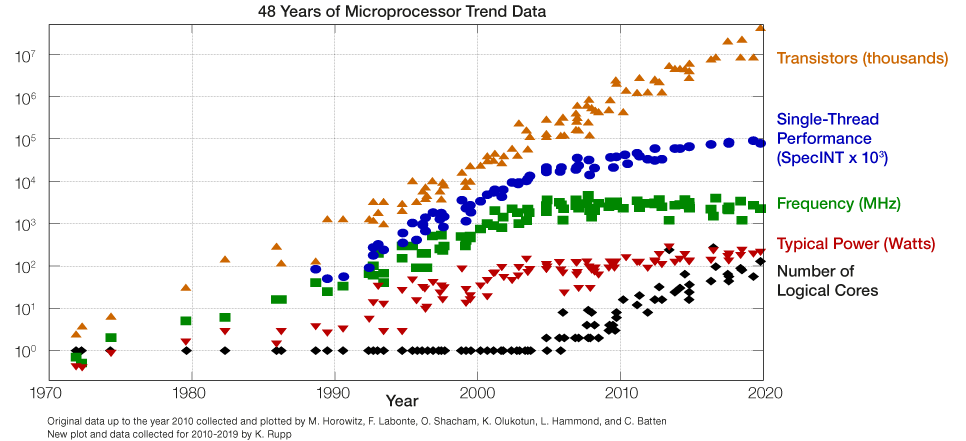 <!-- .element: height="250px" --> --- ## Reduced Instruction Set Computer <div class="row"><div class="col"> <dl> <dt> RISC </dt> <dd> подход к проектированию где набор инструкций сокращён до часто используемых с единым форматом кодирования, что позволяет конвейеризировать исполнение. </dd> </dl> - Можем ли мы ускорить выполнение ограниченного количества инструкций? - Будет ли ограниченное число инструкций эффективно? </div><div class="col"> 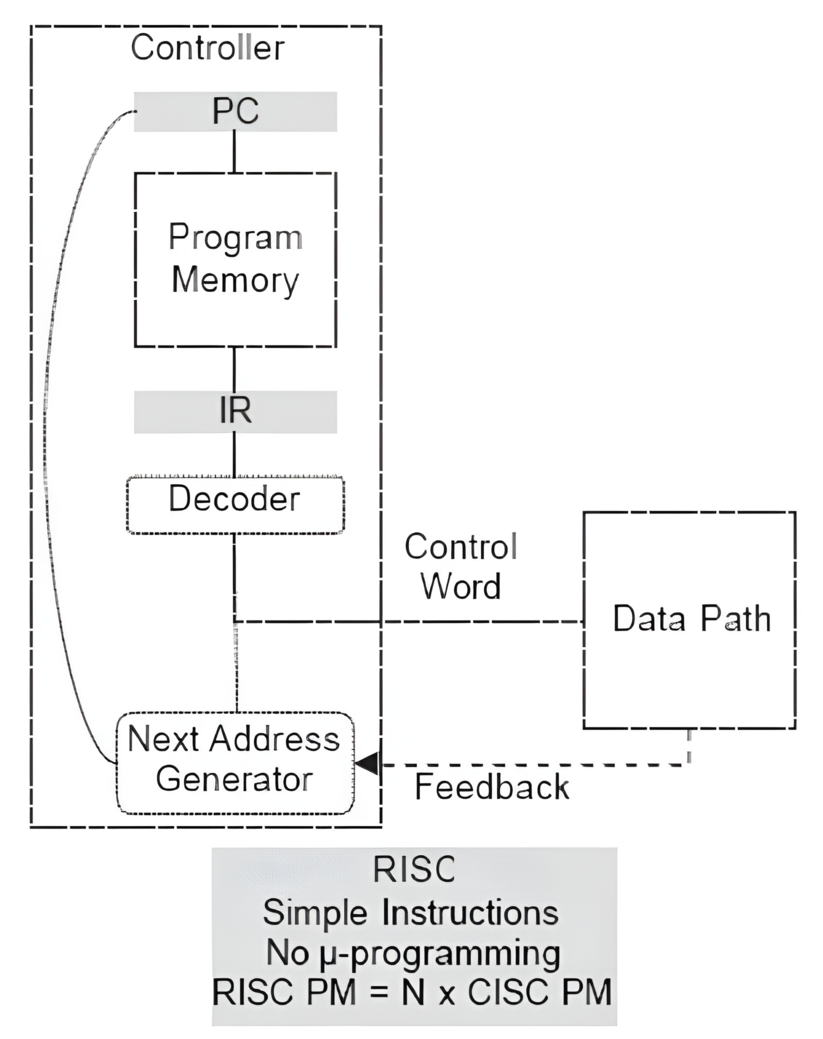 </div></div> ---- ### RISC. Предпосылки и особенности <div class="row"><div class="col"> 1. Сложные операции: - встречаются редко; - заменимы группами команд. 1. Появились ЯП высокого уровня. 1. Единый формат инструкций. Простота декодера инструкций. 1. Место памяти микрокоманд и декодера можно использовать для регистров и кеша. 1. Оптимизация малого количества однообразных команд. 1. Параллелизм уровня инструкций, pipeline. </div><div class="col"> 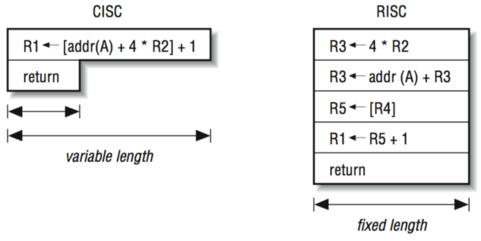 1. "То, что раньше делали корпорации, теперь доступно для двух аспирантов". 1. Рост производительности "средней программы" за счёт ускорения частых инструкций. 1. Простой машинный код. </div></div> --- ### RISC. Pipeline. <br/> Параллелизм уровня инструкций  <!-- .element: height="300px" -->  <!-- .element: height="300px" --> Разбиваем обработку инструкции на несколько этапов и выполняем их параллельно для разных команд. Один такт — одна стадия конвейера. ---- #### Как построить конвейер? 1. выделить стадии выполнения команд; 2. организовать внутренние структуры процессора так, чтобы: - у процессора был входной (поступают команды) и выходной конец (команды "покидают" процессор); - структура процессора должна соответствовать стадиям выполнения команд; - сегменты связаны регистрами, комбинационные схемы сбалансированы; - все части процессора управляются одним тактовым сигналом; 3. загружать в процессор команды каждый такт; 4. получать результаты выполнения команд каждый такт; 5. разрешать конфликты параллельно выполняемых команд. ---- ### RISC. Типовые стадии конвейера <div class="row"><div class="col"> 1. **Instruction Fetch**. Чтение инструкции по счётчику команд. 2. **Instruction Decode**. Декодировать инструкцию и считать регистры. 3. **Instruction Execute**. Операций изменения данных. 4. **Memory Access**. Чтение/запись операндов из памяти/в память. 5. **Write Back**. Запись результата в регистры. </div><div class="col">  <!-- .element: height="350px" --> <small> - Операции: 1. Register-Register (Single-cycle latency): Сложение, вычитание, сравнение и логические операции. 1. Memory Reference (Two-cycle latency): Подготовка адресов для доступа к памяти. 1. Multi-cycle (Many cycle latency): Целочисленное умножение, деление и все операции с плавающей запятой. </small> </div></div> ---- ### RISC. Типовая организация  --- ### RISC. Проблемы конвейеризации Инструкции не являются независимыми друг от друга. 1. Структурные конфликты / Structural dependency 1. Конфликты по данным / Data Dependency / Data Hazard 1. Конфликты по управлению / Control Dependency / Branch Hazards ---- #### Структурные конфликты / Structural Dependency - Конфликт из-за ресурсов. Аппаратура не позволяет выполнить все возможные комбинации инструкций. - Пример: одновременный доступ к единой памяти команд/данных. ```text | Tick | 1 | 2 | 3 | 4 | 5 | | Instr. | | | | | | |---------|------|------|------|-------|-------| | I1 | *IF* | ID | EX | *Mem* | WB | | I2 | | *IF* | ID | EX | *Mem* | | I3 | | | *IF* | ID | EX | | I4 | | | | *IF* | ID | | I5 | | | | ^ | *IF* | | ^ | | Write Back Conflict ---+ | Memory Access | Execution | Instruction Decode | Instruction Fetch ``` - Варианты полного решения проблемы: 1. Гарвардская архитектура. 1. Двухпортовая память. ---- #### Разрешение конфликта пузырьком ```text | Tick | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | | Instr. | | | | | | | | | | |---------|------|------|------|-------|-------|-------|---------|----|----| | I1 | *IF* | ID | EX | *Mem* | WB | | | | | | I2 | | *IF* | ID | EX | *Mem* | WB | | | | | I3 | | | *IF* | ID | EX | *Mem* | WB | | | | - | | | | 0 | 0 | 0 | 0 | 0 | | | - | | | | ^ | 0 | 0 | 0 | 0 | 0 | | - | | | | | | ^ | 0 | 0 | 0 | 0 | | I4 | | | | | | | | ^ | *IF* | ID | EX | | | | | | | push bubbles ---+-------+-------+ ``` - `0` — пузырёк: - занимает конвейер; - не выполняет никаких действий; - просто в реализации; - снижение эффективности. --- #### Конфликты по данным (Hazards) <div class="row"><div class="col"> ##### RAW: Read after Write <br/> (Data-dependency) ```asm and r1 <- __ & __ sub __ <- r1 - __ ```  </div><div class="col"> ##### WAR: Write after Read <br/> (Anti-dependency) ```asm and __ <- r1 & __ sub r1 <- __ - __ ; problem for reordering ``` ##### WAW: Write after Write <br/> (Output dependency) ```asm and r1 <- __ & __ sub r1 <- __ - __ ; problem with caches ``` ##### RAR: (Read after Read) ```asm and __ <- R1 & __ sub __ <- R1 - __ ; not a problem ``` </div></div> ---- ##### RAW — Read after Write (Data-dependency) ```asm and r1 <- __ + __ sub __ <- r1 - __ ``` ```text | Tick | 1 | 2 | 3 | 4 | 5 | 6 | | Stage | | | | | | | |-------|-----|-----|-------|-------|-------|-----| | IF | and | sub | | | | | | ID | | and | sub | | | | | EX | | | and | | sub | | | | MEM | | | | | | and | | sub | | | WB | | | | | | | | and | sub | | | | | 1. exec --+ | | | | | +---- 2.write 3. read --+ | ^ ^ +-- 4. exec | | | | CONFLICT | +--------------------------+ ``` ---- #### Механизмы разрешения Data Hazard 1. Исполнения не по порядку (out-of-order). Компилятор/процессор. ```text i1. R3 <- __ - __ i1. R3 <- __ - __ i2. __ <- R3 + __ => i3. __ <- __ + __ i3. __ <- __ + __ i4. __ <- __ + __ i4. __ <- __ + __ i2. __ <- R3 + __ ``` 1. Переименования регистров. Если зависимость по данным ложная. Запись может быть переназначена на другой регистр (пример WAW). 1. Вставка пузырька. 1. Проброс операндов (bypassing, operand forwarding) между стадиями процессора, минуя регистровый файл. ---- <div class="row"><div class="col"> ##### Проброс операндов <br/> (Bypassing, Operand Forwarding)  - Запись в регистр `i1:WR` - Подмена операнда в `i2:EX` - Проброс значения осуществляется без регистров $\longrightarrow$ в один такт. </div><div class="col"> ##### Bypassing + Bubble   </div></div> --- #### Конфликты по управлению <br/> (Control Dependency, Branch Hazards) - Конфликт из-за операций условного и/или безусловного перехода. - Проблема: в конвейер загружены команды, которые не должны быть исполнены. <div class="row"><div class="col"> Решения: 1. bubble, 1. сброс конвейера, 1. минимизация количества [условных] переходов, - loop unrolling, - условное перемещение данных, 1. предсказание переходов (branch prediction). </div><div class="col">  </div></div> --- ### Branch Prediction #### Статические предсказания переходов Предсказание определяется инструкцией перехода.  1. Условный переход **вперёд** — не произойдёт. 1. Условный переход **назад** — произойдёт (циклы). 1. Некоторые процессоры (Pentium 4) поддерживают "подсказки компилятора" для предсказаний. ---- #### Динамические предсказания переходов Предсказание использует историю переходов программы.  <!-- .element: height="260px" --> 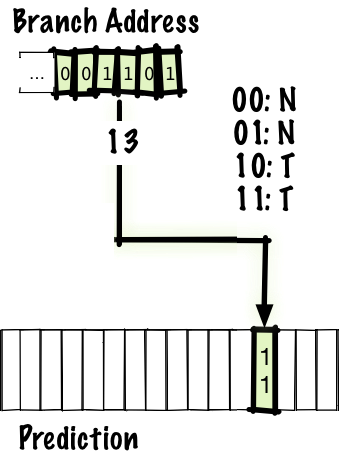 <!-- .element: height="260px" --> Счётчик с накоплением, 2-bit 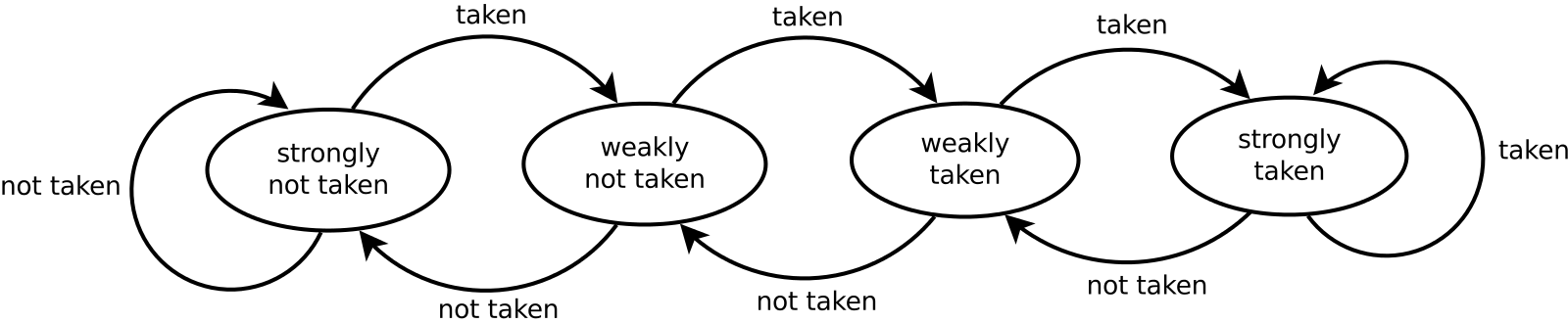 ---- ##### Многоуровневые предсказатели переходов <div class="row"><div class="col"> Проблема: у условного перехода есть периодичность (`11101110...`). </div><div class="col"> ```c // Паттерн: T T T F T T T F ... for (int j = 0; j < N; ++j) for (int i = 0; i < 3; ++i) // code here. ``` </div></div> 1. Correlation-Based Branch Predictor 1. Branch History — Local (specific branch) or Global (all branches) 1. Table sizes. Branch Address collisions. Processes and Threads. 1. Больше деталей: <https://danluu.com/branch-prediction> 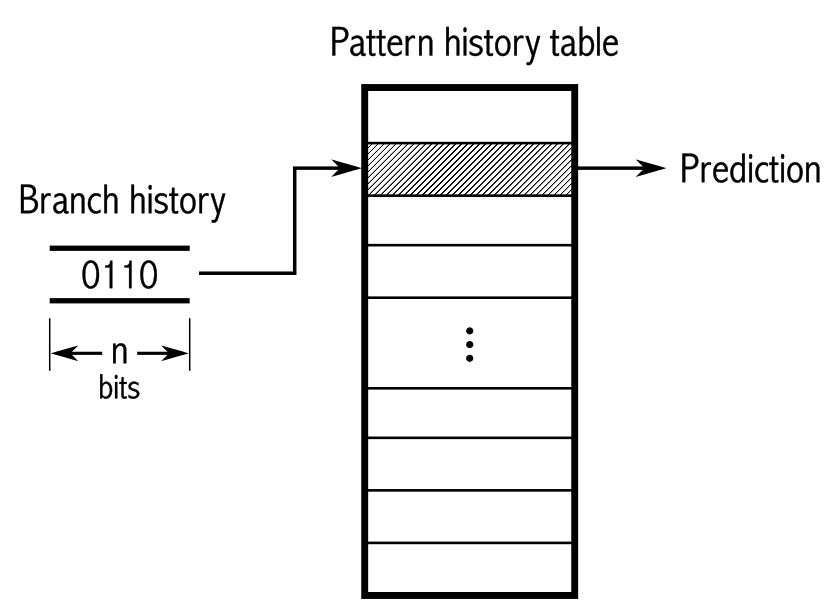 <!-- .element: height="300px" --> 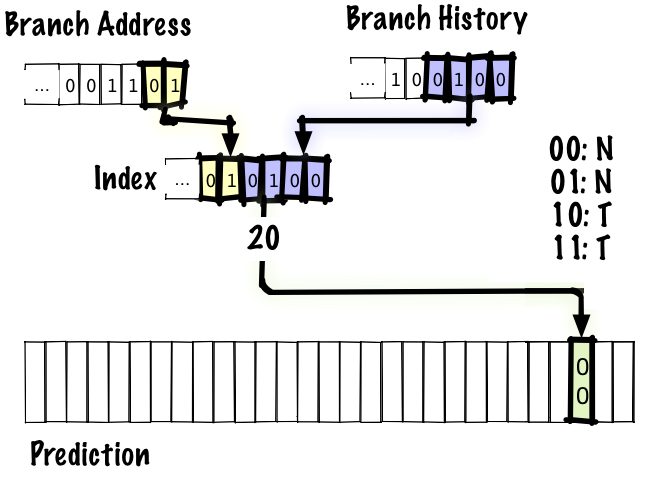 <!-- .element: height="300px" --> --- ### Branch Prediction. Практика ```c++ const unsigned arraySize = 32768; int data[arraySize]; for (unsigned c = 0; c < arraySize; ++c) { data[c] = std::rand() % 256; } #ifdef SORT_DATA std::sort(data, data + arraySize); #endif long long sum = 0; for (unsigned i = 0; i < 100000; ++i) { for (unsigned c = 0; c < arraySize; ++c) { if (data[c] >= 128) sum += data[c]; } } ``` Полный код: [src/branch_prediction.cpp](https://gitlab.se.ifmo.ru/computer-systems/csa-rolling/-/blob/master/src/branch_prediction.cpp) На сколько будет отличаться время работы для сортированного и несортированного массивов? ---- | `branch_prediction_unsorted-O0` | `branch_prediction_sorted-O0` | | ------------------------------- | ----------------------------- | | Elapsed time: 19.5104 | Elapsed time: 3.83967 | | Sum: 312426300000 | Sum: 312426300000 | -------------------- - Оптимизация отключена `-O0` - Скорость работы на несортированном массиве низкая, так как предсказатель переходов часто ошибается. - Скорость работы на сортированном массиве высокая, так как предсказатель переходов не ошибается. - Подробнее: [Why is processing a sorted array faster than processing an unsorted array?](https://stackoverflow.com/questions/11227809/why-is-processing-a-sorted-array-faster-than-processing-an-unsorted-array) ---- #### Branch Prediction. Практика. Оптимизация | `branch_prediction_unsorted-O3` | `branch_prediction_sorted-O3` | |---------------------------------|-------------------------------| | Elapsed time: 1.95652 | Elapsed time: 1.95178 | | Sum: 312426300000 | Sum: 312426300000 | -------------------- - Оптимизация включена `-O3` - if-statement заменяется на инструкцию условной пересылки `cmov`. - Условие не выполнится — пересылка данных не произойдет. - `cmov` не требует сброса конвейера при невыполнении условия. <div class="row"><div class="col"> `-O0` ```asm cmp data[j], 128 jl .if_end mov eax, j mov ecx, eax mov rcx, data[rcx] add sum, rcx ``` </div><div class="col"> `-O3` ```asm cmp edx, 127 cmovle edx, r15d ;r15d always equals 0 add rbx, edx ;rbx = sum ``` </div></div> ---- ##### Разворачивание циклов (Loop Unrolling) <div class="row"><div class="col"> это техника трансформации циклов, которая помогает оптимизировать время выполнения программы за счёт уменьшения количества итераций. Разворачивание циклов увеличивает скорость программы за счет устранения инструкций управления циклом и инструкций проверки цикла. </div><div class="col"> ```c for (int x = 0; x < 100; x++) { delete(x); } ``` $\downarrow$ ```c for (int x = 0; x < 100; x += 5 ) { delete(x); delete(x + 1); delete(x + 2); delete(x + 3); delete(x + 4); } ``` </div></div> ---- #### Количество сброшенных инструкций 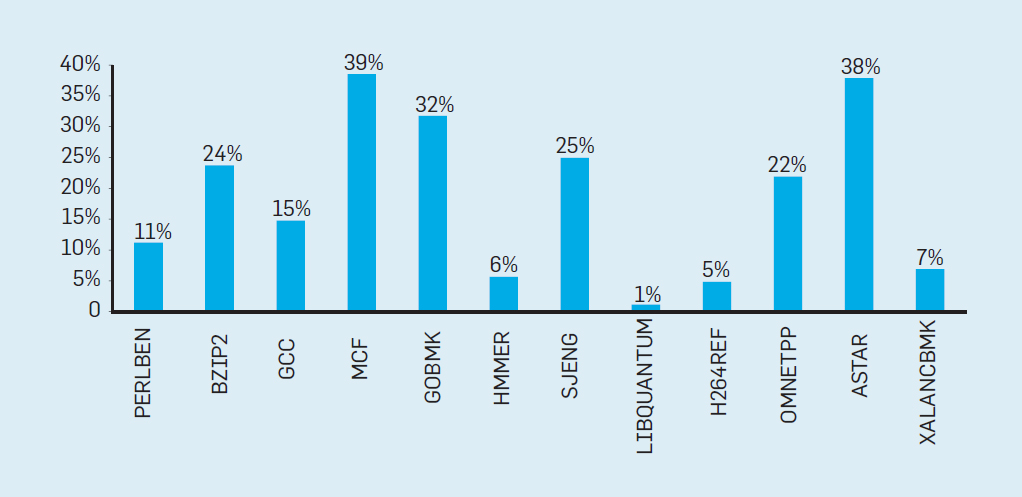 Процессор — Core i7 --- ### Конвейер. Практика | PIC | Core i7 | Pentium 4 | Xeon | Xelerated X10q | |-----|---------|-----------|------|----------------| | 2 | 14 | 20 | 30 | 200 стадий | Преимущества: - повышение производительности и уровня утилизации ресурсов. Недостатки/проблемы: 1. снижение скорости исполнения отдельной команды; 1. не все операции за один машинный цикл; 1. необходимость разрешения конфликтов; 1. непредсказуемое время исполнения; 1. уязвимости "косвенных каналов" ([Meltdown](https://en.wikipedia.org/wiki/Meltdown_(security_vulnerability)), [Spectre](https://en.wikipedia.org/wiki/Spectre_(security_vulnerability))); 1. как быть с виртуальными методами? ---- ### Конвейер. Уязвимости косвенных каналов <div class="row"><div class="col"> **Meltdown** и **Spectre** эксплуатируют спекулятивное исполнение: 1. Процессор **предсказывает** переход и начинает исполнять инструкции «наперёд». 2. При неверном предсказании конвейер сбрасывается, результаты отбрасываются. 3. **Побочные эффекты** (следы в кеше) — остаются. 4. Атакующий измеряет задержки доступа к памяти и восстанавливает «отброшенные» данные. </div><div class="col"> Последствия: - **Meltdown**: утечка данных ядра ОС в пространство пользователя. - **Spectre**: утечка данных между изолированными процессами. - Исправление требует аппаратных изменений **или** потери производительности на 5–30%. > ISA «обещает» последовательное исполнение, <br/> микроархитектура исполняет спекулятивно — это и есть уязвимость. </div></div> Notes: [Meltdown Attack](https://meltdownattack.com) ---- ### RISC. Практика <div class="row"><div class="col"> Почему RISC не победил CISC? Или победил? <div> 1. Мобильные — уже. ПК и сервера — в процессе. 1. Инструментальная поддержка (сколько лет делали `clang`?). 1. Бинарная совместимость (виртуализация, аппаратная трансляция, транспиляция). 1. Зависимость себестоимости от серийности. 1. RISC ядро внутри CISC. </div> <!-- .element: class="fragment" --> </div><div class="col">  </div></div> --- ## Итог. Сравнение архитектур <div class="row"><div class="col"> ```asm ;;;; Acc load ACC <- A ; acc mul ACC <-* B ; 1 operands add ACC <-+ C store Y <- ACC ``` ```asm ;;;; CISC mul R1 <- A * B ; reg-to-mem add Y <- R1 + C ; 2 operands ;; or mul D <- A * B ; mem-to-mem add Y <- D + C ; 2 operands ``` ```asm ;;;; RISC load R1 <- A ; reg-to-reg load R2 <- X ; 2 operands load R3 <- B mul R4 <- R1 * R2 add R5 <- R4 + R3 store Y <- R5 ``` ```forth \\\\ Stack A @ B @ * \ stack, 0 operands C @ + Y ! \ @ - read, ! - write ``` </div><div class="col"> - Acc. Через аккумулятор: - ариф. операции, ввод-вывод. - 1 оп. — явный, 2 — неявный. - CISC. Сложные инструкции. - Переменная длина. - Спец. регистры. - Ариф. операции и доступ(-ы) в память за одну инструкцию. - RISC. Простые инструкции. - Единый размер инструкций. - Операции и работа с памятью — разные инструкции. - Регистры — одинаковые. - Stack. Через стек: - Ариф. операции, ввод-вывод. - Операнды — неявные (часто). </div></div> ---- ### Итог. Таблица сравнения | Характеристика | Accumulator | CISC | RISC | Stack | | ---------------------- | ------------------- | ------------------------ | ------------------------ | ------------------------ | | Операнды | 1 явный + ACC | 1–3 (смешанные) | 2–3 (только регистры) | 0 (стек, неявно) | | Длина инструкции | Переменная | Переменная | Фиксированная | Переменная / фиксир. | | Доступ к памяти | В арифм. инстр. | В арифм. инстр. | Только load/store | push / pop | | Конвейеризация | Сложно | Сложно | Просто | Умеренно | | Сложность компилятора | Низкая | Высокая | Средняя | Низкая | | Типичные примеры | ПДП-8, лаб. 4 | x86, VAX | ARM, MIPS, RISC-V | Forth, JVM | Notes: зависит от алгоритма, неплохо бы оптимизировать под задачу.