# Архитектура компьютера ## Лекция 11 ## Многозадачность. <br/> Система прерываний. <br/> Взаимодействие процессов Пенской А.В., 2026 --- ## Параллелизм 1. Когда нужно работать сразу над несколькими задачами (ввод-вывод, системы управления). 2. Когда нужно повысить уровень утилизации ресурсов (не простаиваем, а занимаемся чем-то полезным). 3. Когда нужно повысить производительность компьютера (делаем больше дел за единицу времени). ### Виды параллелизма 1. **Уровень битов** (Bit-level Parallelism). "Ширина" комбинационных схем, шин данных и машинного слова. 1. **Уровень команд** (Instruction-level parallelism). Параллельное выполнение нескольких инструкций. 1. **Уровень задач** (Task/Thread-level parallelism). Параллельное выполнение нескольких программ. $\longrightarrow$ ---- ### Concurrency vs. Parallelism  <!-- .element: height="350px" -->  <!-- .element: height="350px" --> Сейчас нас интересует **Concurrency**. --- ## Параллелизм уровня задач <div class="row"><div class="col"> **Проблемы**: 1. Архитектура фон Неймана не рассчитана на параллелизм. 1. Поток инструкций — один. 1. Процессор должен "молотить" инструкции до `Halt`. </div><div class="col">  </div></div> Варианты обеспечения параллелизма: 1. Кооперативная многозадачность (Cooperative Multitasking), <br/> соответствующая архитектуре фон Неймана. 2. Вытесняющая многозадачность (Preemptive Multitasking) <br/> или истинная многозадачность. ---- _Question_: Что происходит с контроллером, если он поделит на ноль? --- ## Кооперативная многозадачность (Cooperative Multitasking) <div class="row"><div class="col"> Многозадачность, при которой _следующая задача_ выполняется, когда _текущая задача_ явно объявит о готовности отдать процессорное время. Грубо: есть вызов `Pause`. </div><div class="col">  </div></div> 1. Активная программа получает всё процессорное время. 2. Фоновые — заморожены. 3. Приложение захватывает столько ресурсов, сколько хочет. 4. Приложения делят процессор, передавая управление следующему. ---- ### Cooperative Multitasking. <br/> Вычислительные механизмы 1. Механизм **остановки** выполнения задачи: добровольная передача управления "диспетчеру". 1. Механизм **сохранения** состояния задачи: регистры, стек, состояния сопроцессоров, память, ввод-вывод, кеш, состояние предсказателя переходов, и т.п. 1. Механизм **планирования** — какой задаче отдать процессорное время следующей. 1. Механизм **возобновления** остановленного процесса: восстановление состояния и передача управления. -------------------- 1. Механизмы **изоляции** задач: независимое выполнение, безопасность. 1. Механизмы **взаимодействия** между задачами: передача данных и сигналов, общие ресурсы. ---- ### Cooperative Multitasking. Переключение контекста ```text Время ──────────────────────────────────────────────────────► A ████████████░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░░████████████ ↑ yield() ↑ [save A ctx] [restore A ctx] ↓ ↑ └─── [scheduler: B] ────┘ ↓ [restore B ctx] ↓ B ░░░░░░░░░░░░░░████████████████████████░░░░░░░░░░░░░░░░░░ ↑ yield() [save B ctx] ████ running ░░░░ frozen ``` ctx = { regs, PC, SP, ... } ---- ### Cooperative Multitasking. Анализ <div class="row"><div class="col"> #### Преимущества 1. Контроль за ресурсами со стороны задачи. 1. Известные точки остановки. Отсутствие гонок. 1. Легкость и эффективность (при программной реализации). </div><div class="col"> #### Недостатки 1. Контроль за ресурсами осуществляется задачей. 2. Сбой задачи может быть глобальным. 3. Низкая эффективность и трудоёмкость ввода-вывода. 4. Сложность разработки интерактивных приложений. </div></div> --- ### Cooperative Multitasking. Подходы <div class="row"><div class="col"> 1. Имитация через конечные автоматы (см. прог. ввод-вывод). 1. С диспетчером задач на уровне: - ОС (системные вызовы паузы/передачи управления). - Virtual Machine/Run Time, "шитый код", `time_slice`: - в интерпретаторе, - в машинном коде. - Программный код: - `event-loop` + `callbacks` - `async`/`await`, `yield` </div><div class="col">   </div></div> ---- ### Cooperative Multitasking. Практика 1. Пакетный режим и медленный ввод-вывод (в мейнфреймах), <br/> чтобы освободить процессор на время I/O. 1. Простые встроенные системы, bare-metal программирование. 1. Realtime. Статическое планирование. 1. Оптимизации систем, требующих частого переключения задач: - пример: single thread vs. multi thread web server (nginx/apache); - Node.js. Green Threads $\longrightarrow$  <!-- .element: height="290px" -->  <!-- .element: height="290px" --> ---- #### Green Threads Проблема: как остановить долгую задачу без прерываний и ОС? - **Erlang/OTP**. Green threads are implemented within a virtual machine. The internal scheduler (counting the number of executed instructions for each thread) allows the virtual machine to ensure an even distribution of processor time and meet the requirements of soft real-time. [Erlang Scheduler: what does it do?](https://erlang.org/pipermail/erlang-questions/2001-April/003132.html) <div class="row"><div class="col"> - **Golang**. Go-routines. It is a compromise between cooperative scheduling and OS threads: compiled to machine code, but the language's run-time tracks key points of the algorithm (function calls, channel operations, system calls) to allow scheduling without the operating system. </div><div class="col"> 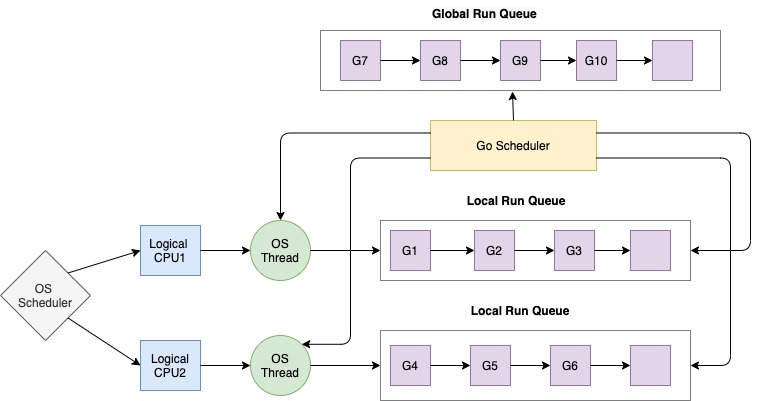 </div></div> **Кооперативная + Вытесняющая**: green threads внутри процесса ОС с вытеснением — пример совместного использования обоих подходов: задачи кооперируют внутри процесса, ОС вытесняет между процессами. --- ## Вытесняющая многозадачность (Preemptive Multitasking) (истинная многозадачность) <div class="row"><div class="col"> ОС передаёт управление между программами в случае _завершения_ операций ввода-вывода, _событий_ в аппаратуре компьютера, _истечения_ таймеров и квантов времени, _поступления_ сигналов. </div><div class="col"> 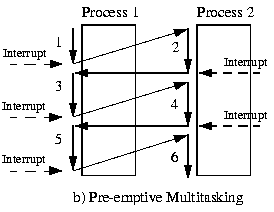 </div></div> 1. Переключение процессов происходит буквально между любыми двумя инструкциями (между — это где на конвейере?). 2. Распределение процессорного времени осуществляется планировщиком. 3. Возможна "мгновенная" реакция на действия пользователя. ---- ### Preemptive Multitasking. <br/> Вычислительные механизмы 1. ~Механизм **остановки** задачи.~ $\longrightarrow$ Механизм **прерывания** процесса — забрать процессор у задачи независимо от её желания. 1. Механизм **сохранения** состояния задачи: регистры, стек, состояния сопроцессоров, память, ввод-вывод, кеш, состояние предсказателя переходов, и т.п. 1. Механизм **планирования** — какой задаче отдать процессорное время следующей. 1. Механизм **возобновления** остановленного процесса: восстановление состояния и передача управления. -------------------- 1. Механизмы **изоляции** задач: независимое выполнение, безопасность. 1. Механизмы **взаимодействия** между задачами: передача данных и сигналов, общие ресурсы. --- ### Система прерываний <div class="row"><div class="col"> Архитектура фон Неймана характеризуется: 1. последовательным исполнением команд и [без]условным переходом; 2. процессор будет "молотить" инструкции столько, сколько сможет; 3. оптимизация "число-дробилки" для одной задачи. </div><div class="col"> Система прерываний позволяет **переключиться** (совершить переход к заданной инструкции) **по внешнему событию** и **вернуться** назад после обработки. 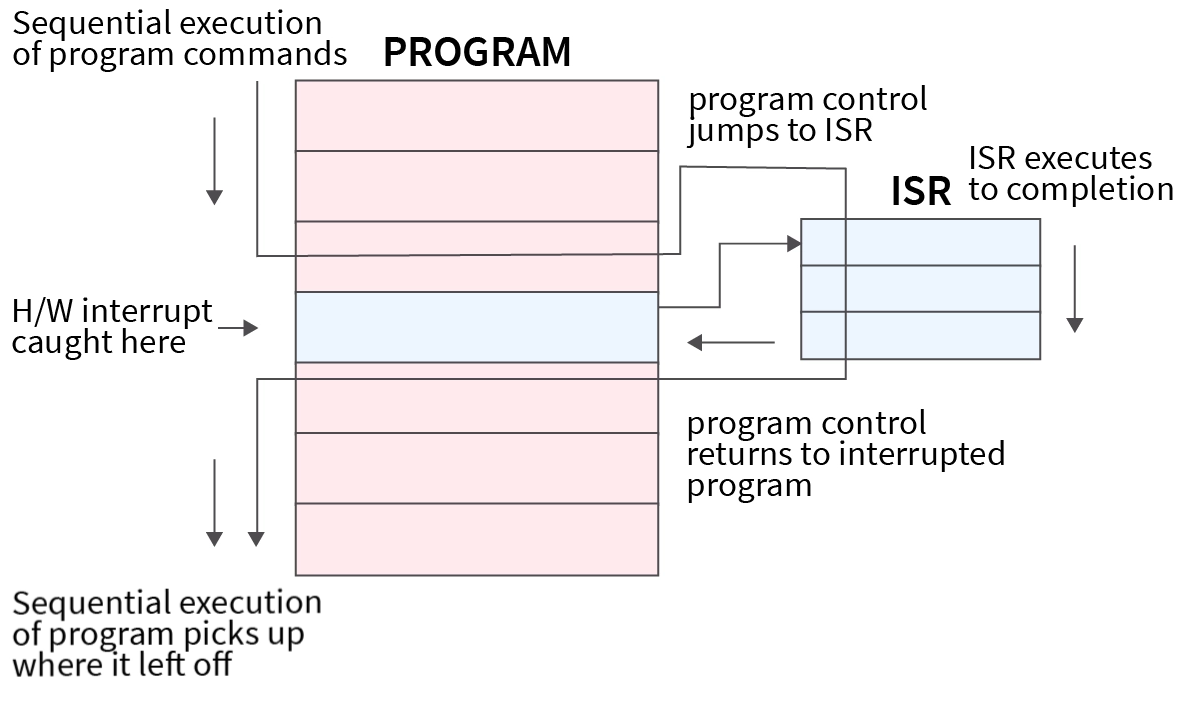 <!--  --> </div></div> ---- ### Система прерываний. Принцип работы <div class="row"><div class="col"> 1. Выполнение "основного" потока. 2. Запрос прерывания (HW). 3. Сохранение адреса возврата. 4. Вызов обработчика прерывания (ISR) — обычного кода в специальном месте. 5. Завершение ISR. 6. Восстановление адреса возврата. 7. Продолжение основного потока. </div><div class="col">  </div></div> Система прерываний обеспечивает минимум два уровня задач: 1. Основной поток исполнения. 2. Поток (потоки) обработчиков прерываний. ---- #### Система прерываний. Источники прерываний 1. **Аппаратные**. 1. **Внешние** (асинхронные для внутренних циклов процессора): переполнение таймера, нажатие клавиши, сетевой пакет. 1. **Внутренние** (синхронные): деление на `0`, ошибка доступа к памяти, и т.п. 1. **Программные** (вызывается инструкцией): взаимодействие программы и ОС.  ---- #### Система прерываний. Контроллер прерываний <div class="row"><div class="col"> 1. Обычно, реализуется аппаратно (скорость и параллелизм). 2. Конкурирующие прерывания (приоритеты, потери, очереди): - Маскируемые/Немаскируемые. - Относительные/Абсолютные (прерывает прерывание). 3. Вид события/прерывания (см. далее). </div><div class="col">  </div></div> ---- #### Виды событий: по линии IRQ <div class="row"><div class="col"> **По фронту (edge-triggered)** - Прерывание генерируется в момент **изменения уровня** сигнала (0→1 или 1→0). - Реагирует на сам факт перехода, не на состояние линии. - Не требует сброса сигнала после обработки. - Минус: фронт можно «потерять», если контроллер был занят. </div><div class="col"> **По уровню (level-triggered)** - Прерывание активно, **пока сигнал на линии активен**. - Источник или обработчик обязан **сбросить** сигнал после обработки. - При объединении источников по ИЛИ (shared IRQ) — ложные прерывания (spurious): один источник обслужен, но линия активна из-за другого. - Зато ничего не теряется: запрос «висит», пока его не обслужат. </div></div> ---- #### Виды событий: запись в регистр <div class="row"><div class="col"> **По сообщению (Message Signaled, MSI)** - Прерывание инициируется **записью сообщения** в регистр процессора / контроллера прерываний. - Нет выделенной физической линии на каждое устройство → лучше **масштабируется** (PCIe). - Сообщение само несёт информацию **об источнике и типе** — не нужен опрос. </div><div class="col"> **По дверному звонку (Doorbell)** - Одно устройство инициирует событие у другого **записью в его регистр**. - **Сигнал и данные разнесены**: запись — это уведомление, сами данные лежат в памяти. - Используется для уведомления о готовой к обработке порции работы (GPU, NIC, межъядерные взаимодействия). </div></div> ---- ### Система прерываний. Пример. Кнопка ```text Polling Прерывание CPU ──?──?──?──?──!──?──► CPU ──────────────[ISR]────► ↑ ↑ ↑ check react IRQ BTN ─────────┐ BTN ─────────┐ └────────── └── IRQ ──► ISR ? = read & compare IRQ: save PC → jump ISR ! = counter++ ISR: counter++ → reti ``` --- ### Система прерываний. SPI — Master Программно-управляемый ввод-вывод и таймер. <div class="row"><div class="col"> 1. Начало передачи: - Настройка таймера. Вкл. прерывания. - `CS = 0` - `MOSI = o.pop()` 1. На каждое прерывание таймера: - `SCLK = !SCLK` - `if (!SCLK) MOSI = o.pop()` - `if ( SCLK) i.push( MISO )` 1. Окончание передачи: - `CS = 1` - `ready_flag = 1` `i` - input, `o` - output </div><div class="col">  (длительность — произвольна)  </div></div> ---- ### Система прерываний. SPI — Slave <div class="row"><div class="col"> 1. Прерывание от **CS** (negedge): - Вкл. прерывания от **SCLK**. - `MISO = o.pop()` 1. Прерывание от **SCLK** (both): - `SCLK = !SCLK` - `if (!SCLK) MISO = o.pop()` - `if ( SCLK) i.push( MOSI )` 1. Прерывание от **CS** (posedge): - Выкл. прерывания от **SCLK**. - `ready_flag = 1` `i` - input, `o` - output -------------------- Альтернатива: вся передача данных программно внутри прерывания. </div><div class="col">  (длительность — произвольна)  </div></div> --- ### Система прерываний. Пример. Watchdog Timer **Сторожевой таймер** — _аппаратно_ реализованная схема контроля от зависания системы. A **watchdog timer** is an _electronic or software_ timer that is used to detect and recover from computer malfunctions.  <!-- .element height="220px" -->  <!-- .element height="400px" --> --- ### Preemptive Multitasking. Анализ <div class="row"><div class="col"> #### Преимущества PM 1. Простота разработки ПО с одним процессом. 1. Контроль за ресурсами со стороны ОС. Изоляция. 1. Интерактивность системы (почти мгновенная реакция). </div><div class="col"> #### Недостатки PM 1. "Лишние" переключения. 1. "Тяжесть" процессов (прерывания, состояния, и т.п.). 1. Разделяемые состояния и непредсказуемые переключения. Синхронизация. Гонки. 1. Непредсказуемая длительность работы. Реальное время. </div></div> - Почему потоки — это фундаментальная проблема арх. фон Неймана? - [The Problem with Threads](https://www2.eecs.berkeley.edu/Pubs/TechRpts/2006/EECS-2006-1.pdf) - Максимальная длительность остановки процесса? - [Checkpoint/Restore In Userspace, or CRIU](https://criu.org/Main_Page) - Почему это очень сложно (пример)? $\longrightarrow$ ---- <div class="row"><div class="col"> #### MapReduce  1. `split data set` <br/> `:: [a] -> [[a]]` 1. `map foreach data set` <br/> `:: [[a]] -> [[b]]` 1. `reduce data sets` <br/> `:: [[b]] -> c` -------------------- Проблема: <span> ошибки и остановка. </span> <!-- .element: class="fragment" --> </div><div class="col">  <!-- .element height="620px" --> </div></div> --- ## Сосуществование задач Параллелизм требует (оба вида): 1. Обеспечить **совмещение** и **изоляцию** между задачами. 1. Обеспечить **взаимодействие** между задачами. Предмет совмещения: - процессорное время; - **память/регистры**. Что надо совместить/изолировать? $\longrightarrow$ ---- Что надо совместить/изолировать? - Регистры. - Адреса инструкций (переходы). - Адреса данных (переменных). - Динамическую память (куча). - Автоматическую память (стек). -------------------- Когда надо совмещать/изолировать? - _Compile-time_ (состав задач фиксирован). - _Run-time_ (состав задач динамический). ---- ### Как совместить две задачи по памяти? 1. Инструкции: - **Размещаем** инструкции в разных областях памяти. - **Корректируем** все абсолютные адреса переходов. 1. Данные: - **Размещаем** данные в разных областях памяти. - **Корректируем** все абсолютные адреса. 1. Регистры: - **Формируем** соглашение о вызове процедур внутри задач. - **Сохраняем** и **загружаем** регистры между задачами. 1. Автоматическая память: - **Оцениваем** потребность в памяти. - **Выделяем** подходящие диапазоны (фрагментация). 1. Динамическая память: **выделяем** диапазон. 1. **Верим** в "добросовестное использование". --- ### Изоляция памяти 1. Банки памяти (Memory Bank), отчасти 1. Сегментация (Segmentation) 1. Виртуальная память (Virtual Memory) --- ### Банки памяти (Memory Bank) <div class="row"><div class="col"> Когда используется: 1. Память имеет большее адресное пространство, чем процессор. 1. Расширение машинного слова. 1. Переключение режима работы (аппаратная изоляция). 1. Изоляция задач — редко.  </div><div class="col"> - Расширение машинного слова: - два чипа памяти параллельно; - младший бит адреса `0` и `1` — выбор чипа; - машинное слово процессора — $2*8 = 16$ бит. - Расширение памяти, изоляция: - адрес в процессоре — 8 бит; - `+ 2` бит выбора банка памяти; - итого: 10 бит адреса. - (схемы дальше) </div></div> ---- #### Банки памяти. Расширение памяти и изоляция  <!-- .element height="440px" -->  <!-- .element height="440px" --> Notes: A hypothetical memory map of bank-switched memory for a processor that can only address 64 KB. This scheme shows 200 KB of memory, of which only 64 KB can be accessed at any time by the processor. The operating system must manage the bank-switching operation to ensure that program execution can continue when part of memory is not accessible to the processor. --- ### Сегментная память (Segmentation) Разметим память процессора по назначению. <br/> Как внутри задач, так и между ними. <div class="row"><div class="col"> 1. Сегментная адресация памяти — способ логической адресации памяти, где адрес: `сегмент` + `смещение`. 1. `Сегмент` — выделенная область адресного пространства **определённого размера**. 1. `Смещение` — адрес ячейки памяти относительно начала сегмента. </div><div class="col">  </div></div> ---- #### Сегментная память. Позволяет <div class="row"><div class="col"> 1. Независимая адресация внутри сегментов (нет коллизиям). 1. Управление доступом (чтение, запись). Запрет доступа к "чужим" сегментам. 1. Взаимодействие задач через общий сегмент. 1. Изоляция программных модулей, динамические библиотеки (ПО — 1, data — N). 1. Перекрытие сегментов. $\downarrow$ </div><div class="col">  </div></div> ---- 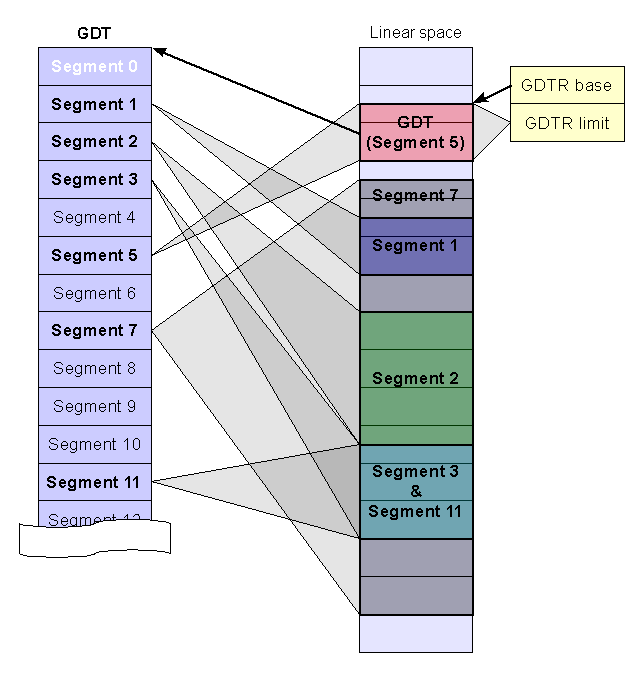 ---- #### Сегментная память. Анализ <div class="row"><div class="col"> ##### Segmentation. Достоинства 1. Таблицы сегментов относительно малы. 1. Таблицы сегментов просты в обработке и перемещении. 1. Средние размеры сегментов больше, чем размеры большинства страниц, что позволяет хранить в сегментах больше данных процесса. 1. Отсутствует внутренняя фрагментация. </div><div class="col"> ##### Segmentation. Недостатки 1. Non-von Neumann way - Поддержка со стороны компилятора, ПО. - Участие программистов (количество сегментов, размер сегментов). 1. Считается устаревшей, имеет ограниченную поддержку ОС (Linux). 1. Внешняя фрагментация. $\longrightarrow$ </div></div> ---- <div class="row"><div class="col"> #### Внутренняя фрагментация 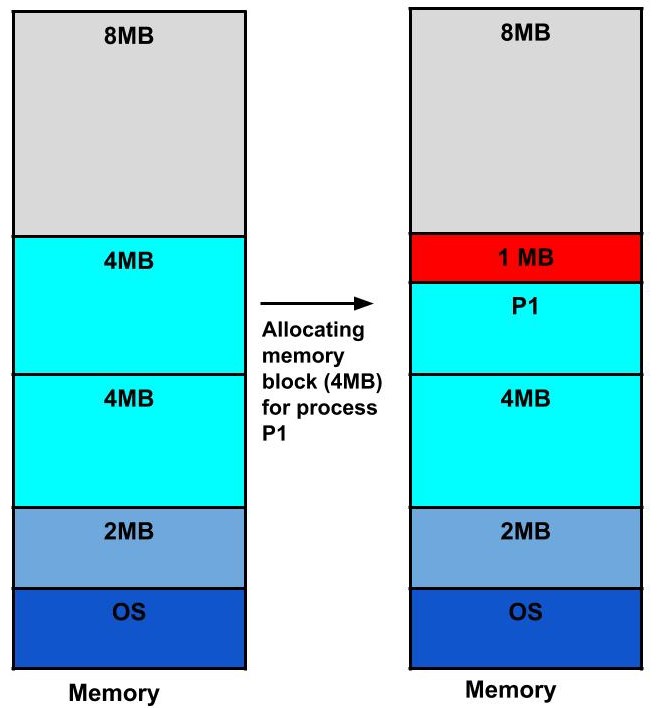 <!-- .element height="400px" --> Данные размещаются в блоках фиксированного размера. <br/> `P1` — требует 3 Mb, блок — 4 Mb. </div><div class="col"> #### Внешняя фрагментация 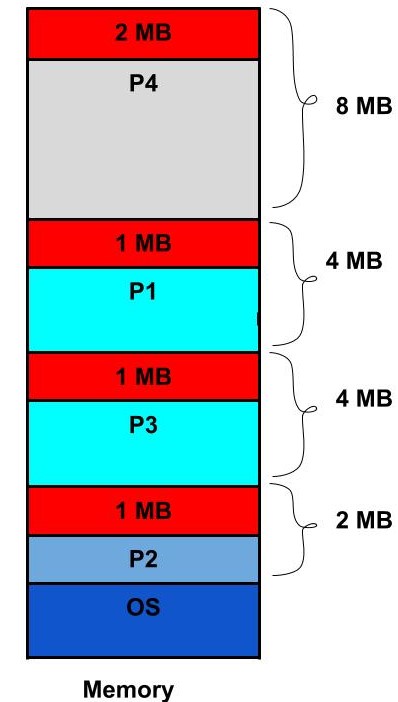 <!-- .element height="400px" --> Данные размещаются в блоках произвольных размеров. <br/> Проблема плотной укладки. </div></div> --- ### Виртуальная память (Virtual Memory) Предоставим каждой задаче своё виртуальное адресное пространство. <br/> Пусть каждый процесс думает, что **всё адресное пространство его**. <div class="row"><div class="col"> 1. **Режем** вирт. адресные пространства на страницы. 1. **Отображаем** страницы на физические адреса по запросу. 1. **Физическая память кончилась**: - **находим** неиспользуемые страницы любой задачи; - **выгружаем** их на диск. 1. **Страницы нет** в физической памяти: - **загружаем** её с диска. </div><div class="col"> 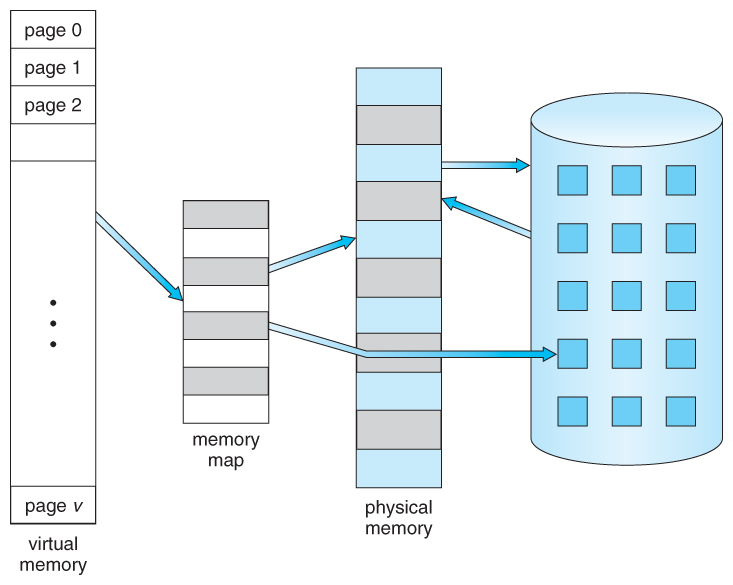 </div></div> ---- #### Виртуальная память. Позволяет <div class="row"><div class="col"> 1. Прозрачно для программиста изолировать задачи. 1. Нелинейное физическое размещение данных. 1. Не фиксировать объём памяти, используемый задачей. 1. Использовать больше памяти, чем есть физически. Выгрузка на диск части задачи (задач). 1. Права доступа. Отображение страниц на разные адресные пространства. </div><div class="col">   <!-- .element height="230px" -->  <!-- .element height="230px" --> </div></div> ---- <!-- Вопросы: --> <!-- 1. Как выглядит работа компьютера без виртуальной памяти? --> <!-- 1. Что лучше: страничная или сегментная организация памяти? --> <!-- ---- --> #### Виртуальная память. Анализ <div class="row"><div class="col"> ##### ВП. Достоинства 1. Прозрачна для программистов. 1. Работа с "бесконечной" памятью, динамическое распределение памяти. 1. Повышает общую стабильность системы (аналогично Preemptive Multitasking). 1. Отсутствует внешняя сегментация. </div><div class="col"> ##### ВП. Недостатки 1. Большой объём таблиц страниц, длительный поиск (кеш). 1. Высокие накладные расходы (ввод-вывод, перенос страниц...) 1. Нет изоляции внутри адресного пространства. 1. Непредсказуемая длительность доступа к памяти. 1. Высокая сложность реализации. </div></div> --- ### Взаимодействие между задачами <div class="row"><div class="col"> Типовые виды задач (условно): 1. **Main**/Kernel/Основной поток — исходный поток инструкций. 1. **Прерывания**. Особый исходный код обработчиков прерываний. 1. **Процессы**. Изолированные адресные пространства. Нет прямого доступа. 1. **Потоки**. Работают в адресном пространстве процесса. Прямой доступ ко всем его данным. 1. **Зелёные потоки**. В рамках Run-Time или виртуальной машины. (_подробнее в курсе ОС_) </div><div class="col">  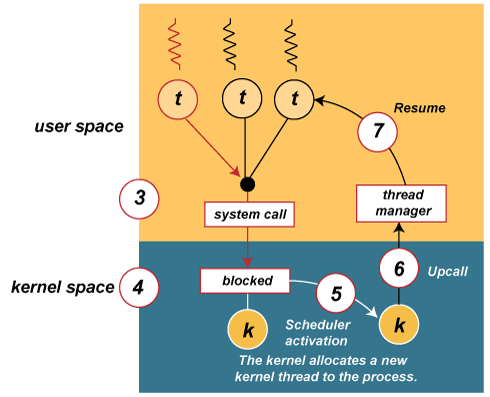 </div></div> ---- #### Взаимодействие процессов <div class="row"><div class="col"> **Проблема**: как получить доступ к изолированной памяти. 1. Shared Memory 1. Signals 1. IO: Network, Files, Pipes </div><div class="col"> 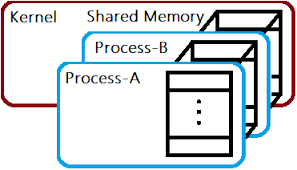 </div></div>  <!-- .element height="350px" --> ---- #### Взаимодействие потоков <br/> (вытесняющая многозадачность) **Проблема**: непредсказуемая последовательность исполнения инструкций с недетерминированным результатом. **Решение**: искусственная синхронизация процессов. 1. Атомарные операции: `compare&swap`, `conditional store` и т.п. 1. Mutex `(0/1)`, Semaphore `(0..N)`. 1. [Software] Transactional Memory ([S]TM). 1. Process Network, Promise, Futures, Actor-Model... --- ## Детерминизм многопоточности /1 <div class="row"><div class="col"> ```c // Глобальные переменные с // разделяемым состоянием. int x, y, a, b; // Два зеркальных потока. void* thread1(void* unused) { x = 1; a = y; return NULL; } void* thread2(void* unused) { y = 1; b = x; return NULL; } ``` Возможна ли остановка алгоритма? </div><div class="col"> ```c int main() { int i = 0; while (1) { x = 0; y = 0; a = 0; b = 0; pthread_t tid1, tid2; pthread_attr_t attr1, attr2; pthread_attr_init(&attr1); pthread_attr_init(&attr2); pthread_create(&tid1, &attr1, thread1, NULL); pthread_create(&tid2, &attr2, thread2, NULL); pthread_join(tid1, NULL); pthread_join(tid2, NULL); i++; if(a == 0 && b == 0) break; } printf("Iterations: %d\n", i); return 0; } ``` </div></div> ---- ### Детерминизм многопоточности в теории | | | | | | `a/b` | |:----------|:---------|:------------|:------------|:------------|:-----:| | `thread1` | `1 -> x` | `y(0) -> a` | | | `0` | | `thread2` | | | `1 -> y` | `x(1) -> b` | `1` | | | | | | | | | `thread1` | `1 -> x` | | `y(1) -> a` | | `1` | | `thread2` | | `1 -> y` | | `x(1) -> b` | `1` | | | | | | | | | `thread1` | `1 -> x` | | | `y(1) -> a` | `1` | | `thread2` | | `1 -> y` | `x(1) -> b` | | `1` | | | | | | | | | `thread1` | | | `1 -> x` | `y(1) -> a` | `1` | | `thread2` | `1 -> y` | `x(0) -> b` | | | `0` | При любом **последовательном** порядке выполнения инструкций: нет. ---- ### Детерминизм многопоточности. Модель памяти Реальные процессоры не гарантируют **последовательную согласованность** (Sequential Consistency). - Запись попадает в **store buffer** и не сразу видна другим ядрам. - Чтение может обогнать ещё не сброшенную запись. ```text thread1: [x=1 → buffer] [a=y(0)] ← читает y до сброса буфера thread2 thread2: [y=1 → buffer] [b=x(0)] ← читает x до сброса буфера thread1 ``` Итог: `a=0, b=0` — невозможно в теории, но **наблюдается на практике**. ---- ### Детерминизм многопоточности на практике ```shell $ clang src/thread-magic.c $ ./a.out Iterations: 27243 $ ./a.out Iterations: 297675 $ ./a.out Iterations: 4302 ``` Да. Источник: [Другой взгляд на многопоточность](https://habr.com/en/post/590339/) --- ## Вернёмся к вводу-выводу 1. Программно-управляемый ввод-вывод — операции реализуются процессором. Все действия реализуются через инструкции процессора. 2. Ввод-вывод по прерыванию. Снимает с процессора задачу наблюдения и позволяет это реализовать по внешнему событию. 3. **Channel I/O** и **прямой доступ к памяти** (Direct Memory Access — DMA). Процессор ставит задачу и оповещается по готовности. ---- ### Channel I/O. Процессоры ввода-вывода - Позволяют задать программу для взаимодействия с внешним устройством. К примеру: "считать запись на диске, идентифицированную записанным ключом": ```text SEEK <cylinder/head number> SEARCH KEY EQUAL <key value> TIC *-8 Back to search if not equal READ DATA <buffer> ``` - ISA канала адаптирована для ввода-вывода (пример: автоматическая конвертация форматов). - Ранее применялись в мэйнфреймах. - Сегодня вытеснено (упрощено до) DMA. --- ### Прямой доступ к памяти (DMA) - Как освободить процессор от работы с вводом-выводом? - Добавить больше процессоров! - Direct Memory Access (DMA). - Выполняет команды переноса данных между памятью устройств ввода-вывода и памятью процессора. 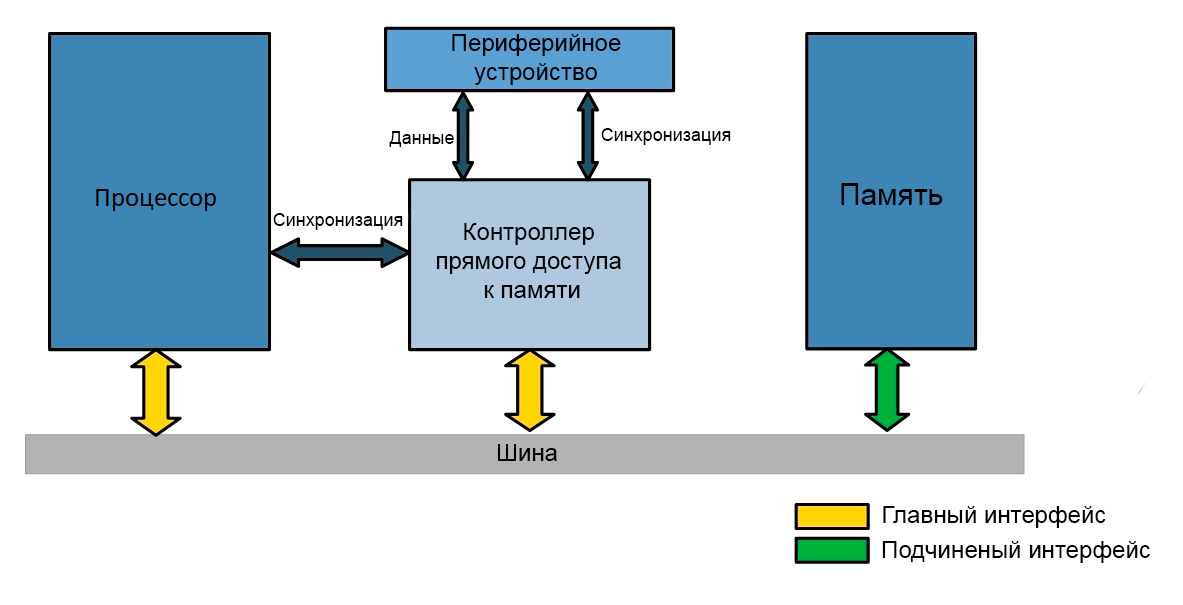 <!-- .element height="375px" --> ---- #### Прямой доступ к памяти. Интерфейс ```c DMA_SRC_ADDR // Исходный адрес (откуда читать) DMA_DST_ADDR // Целевой адрес (куда писать) DMA_COUNT // Количество байт/слов для передачи DMA_CONTROL // Управление (направление, режим работы, запуск/остановка) DMA_STATUS // Статус (занят/готов, ошибки) ``` ```text ┌───────────┐ ┌──────────────┐ ┌───────────┐ │ │◄─────────┤ │◄─────────┤ │ │ │ Данные │ DMA │ Данные │ │ │ Память │ │ Контроллер │ │ Устройство│ │ │─────────►│ │─────────►│ (UART/SPI)│ │ │ Данные │ │ Данные │ │ └───────────┘ └──────────────┘ └───────────┘ ▲ ▲ │ │ └───────────┬───────────┘ │ ┌─────▼─────┐ │ │ │ Процессор │ │ │ └───────────┘ ``` ---- #### Прямой доступ к памяти. Интеграция в систему - **Third-party**. Управление DMA осуществляется процессором. - **Bus mastering**. Управление DMA может осуществляться и устройствами ввода-вывода. -------------------- #### Прямой доступ к памяти. <br/> Взаимодействие с процессором - **Пакетный режим** (Burst Mode). Приоритет DMA. Передача данных осуществляется единой операцией, которая не может быть прервана процессором. - **Циклический режим** (Cycle stealing mode). <br/> Приоритет конфигурируется. Для процессора и DMA выделяется фиксированный слот времени в рамках цикла. - **Прозрачный режим** (Transparent Mode). Приоритет процессора. Передача данных, когда процессор не взаимодействует с памятью. ---- #### Прямой доступ к памяти. Достоинства 1. Скорость и эффективность контроллера DSA. 1. Интерактивность, так как процессор разгружен от "рутины". 1. Параллелизм: DMA может иметь несколько каналов для параллельной работы. -------------- #### Прямой доступ к памяти. Недостатки 1. Проблемы совместимости. 1. Сложность при непоследовательном доступе к памяти. 1. Ограниченный контроль за системной шиной. Синхронизация работы процессора и DMA. 1. Конфликты использования DMA разными устройствами ввода-вывода. --- ## Тенденция: <br/> унификация и упрощение - Memory-Mapped IO (отображение интерфейсов в память) - Direct Memory Access (представление протокола передачи как перемещения данных в памяти) - Virtual Memory (Унификация памяти с точки зрения процесса) Итого: **всё есть память и она одна.** ---- ### Операционные системы: всё есть файл 1. **Универсальный интерфейс**: - Все ресурсы системы представлены как файлы. - Единый набор операций: открытие, чтение, запись, закрытие. 2. **Простота и управляемость**. Использование общих инструментов для манипуляций с различными ресурсами. 3. **Прозрачность системы**. Все взаимодействия с ресурсами легко отслеживаются. 4. **Масштабируемость и распределённость**. Локальные и удалённые ресурсы доступны через одинаковые интерфейсы. ---- #### Пример: Linux Исключения: 1. **Сетевые интерфейсы**: `socket()`, `bind()`, `listen()`, `accept()`. 2. **Процессы и потоки**: `/proc` — информация о процессах, но не управление. 3. **Аппаратные устройства** (некоторые) 4. **Специальные файловые системы** sysfs и devfs, которые предоставляют интерфейсы к устройствам и ядру, но их поведение отличается от обычных файлов. 5. **Графические интерфейсы**. ---- #### ОС: Всё есть файл: Plan 9 - Файловая система `/net`: - Каждое сетевое соединение представлено как файл. - Создание и управление соединениями через стандартные файловые операции. -------------------- ##### Процесс установки TCP-соединения 1. Открытие файла `/net/tcp/clone`: - Система возвращает файловый дескриптор для нового соединения. - Автоматическое создание файлов `ctl`, `data`, `status` для управления соединением. 2. Управление соединением через файл `ctl`: - Команды для настройки IP-адреса, порта и других параметров. 3. Обмен данными через файл `data`: - Передача и приём данных посредством чтения и записи в файл.