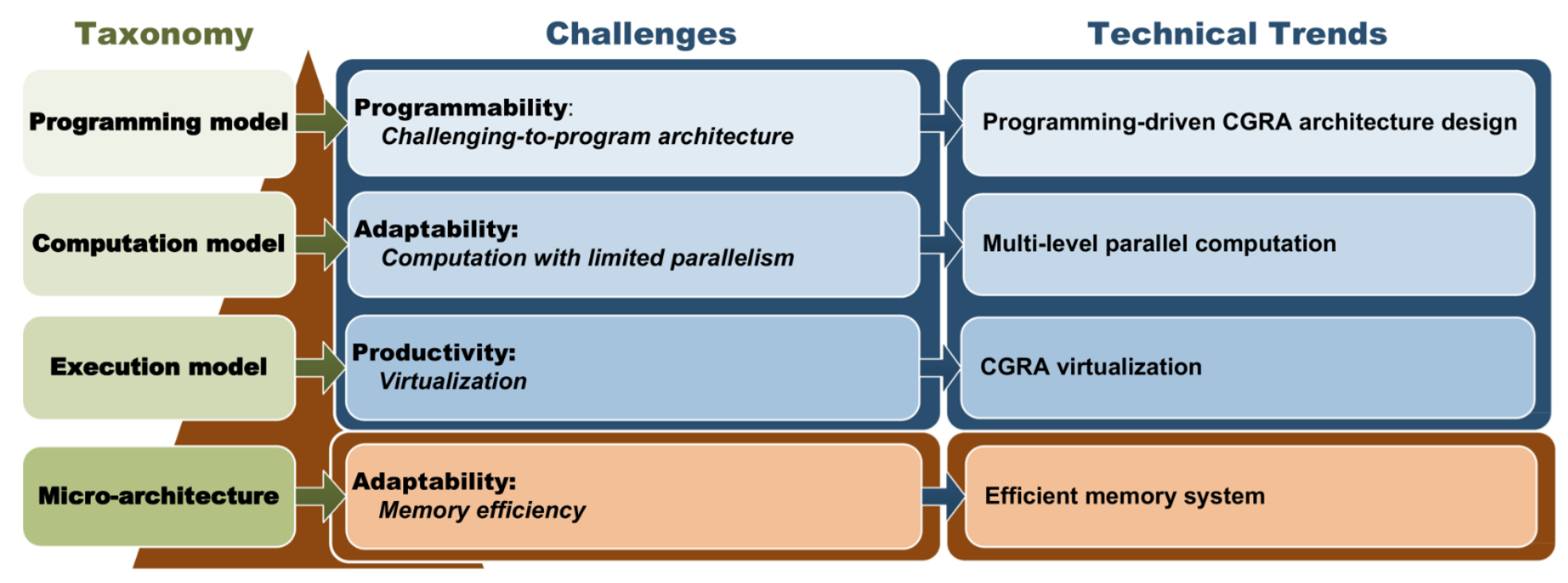
# Архитектура компьютера ## Лекция 16 ## Классификация Дункана. CGRA Пенской А.В., 2026 --- ## Классификация Дункана <div class="row"><div class="col"> Задачи: 1. Абстрагироваться от низкоуровневого параллелизма (конвейер, суперскаляр, VLIW). 1. Переиспользовать элементы таксономии Флинна от 1966. 1. Актуализировать и включить новинки на 1990 год. 1. Навести порядок в MIMD. -------------------- - Достоинства: относительная полнота. - Недостатки: сложность, "искусственность". - Новинки отмечены: `*`. </div><div class="col"> 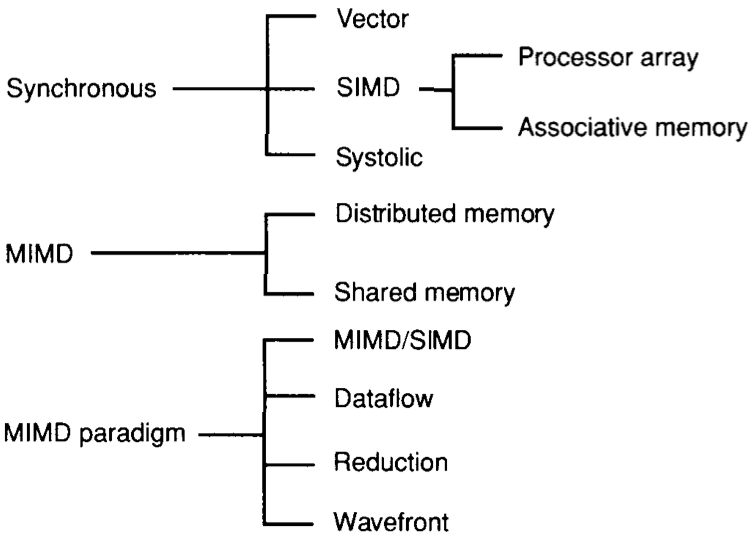 [Duncan, Ralph, "A Survey of Parallel Computer Architectures", IEEE Computer. February 1990, pp. 5-16.](https://ieeexplore.ieee.org/document/44900) </div></div> ---- ### Классификация Дункана. Уровень 1 1. **Синхронные архитектуры** Параллельные архитектуры с единым механизмом управления (глобальные часы, центральный блок управления и т.п.). **Различаются механизмами синхронизации**. 1. **MIMD архитектуры** Параллельные архитектуры, которые могут исполнять независимые потоки инструкций. Потоки инструкций исполняются автономно, требуется динамическая синхронизация. **Различаются структурой организации памяти**. 1. **MIMD парадигма** (MIMD paradigm architectures) Архитектура MIMD процессора определяется моделью вычислений (MoC). MoC определяет характер потоков данных, принципы взаимодействия и синхронизации. **Различаются MoC**. --- ### Синхронные архитектуры Класс процессорных архитектур, обладающих единым/централизованным/синхронным управлением, определяющим поведение всего процессора в целом. - Векторные архитектуры. - SIMD архитектуры: - Процессорные массивы. - Ассоциативные массивы. - Систолические массивы. - Совмещение памяти и вычислений`*`. ---- #### Sync. Векторные архитектуры <div class="row"><div class="col"> <dl> <dt> Скалярная величина </dt> <dd> величина, которая может быть представлена числом (целочисленным или с плавающей точкой). </dd> </dl> -------------------- <dl> <dt> Вектор </dt> <dd> величина, представленная последовательностью скалярных величин. </dd> </dl> -------------------- Векторные операции — операции, выполняемые на последовательностях данных. </div><div class="col"> ```c for (i = 0; i < 10; i++) c[i] = a[i] + b[i]; ``` ```asm move $10, count ; count := 10 loop: load r1, a load r2, b add r3, r1, r2 ; r3 := r1 + r2 store r3, c add a, a, $4 ; move on add b, b, $4 add c, c, $4 dec count ; decrement jnez count, loop ; loop back if count != 0 ``` ```asm ; v1, v2, v3 -- vector registers move $10, count ; count = 10 vload v1, a, count vload v2, b, count vadd v3, v1, v2 vstore v3, c, count ``` </div></div> ---- ##### Векторные архитектуры. Устройство 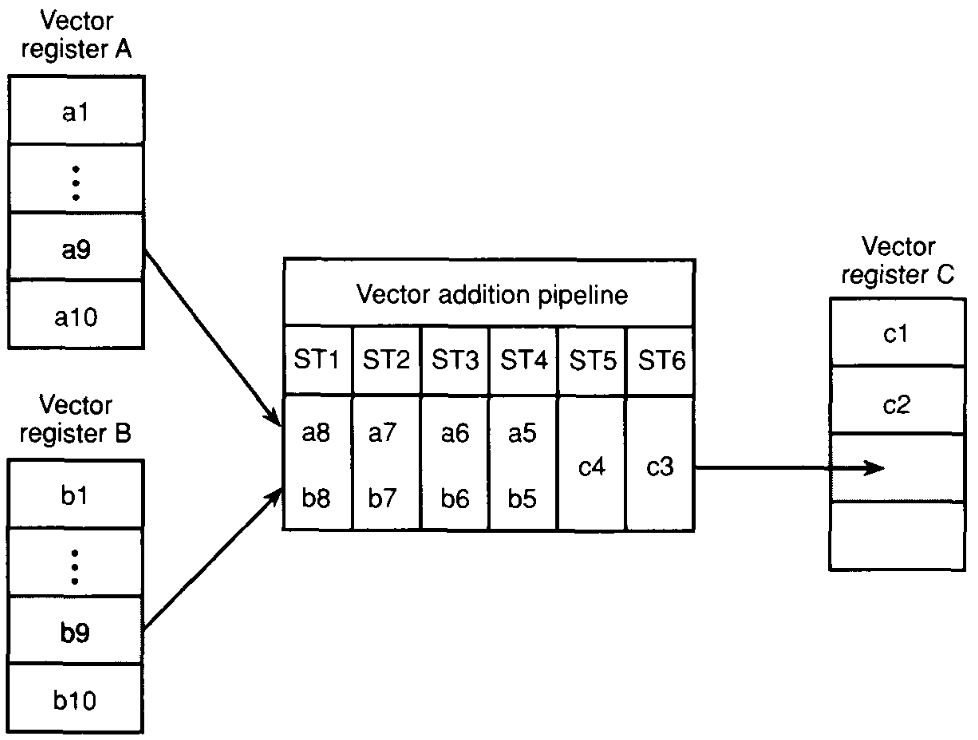 <!-- .element: height="400px" --> 1. Сокращение количества обрабатываемых инструкций. 1. Конвейерное исполнение векторных операций. 1. Множество функциональных узлов (суперскалярность). ---- #### Sync. SIMD Архитектуры Single Instruction Multiple Data ##### SIMD. Процессорные массивы 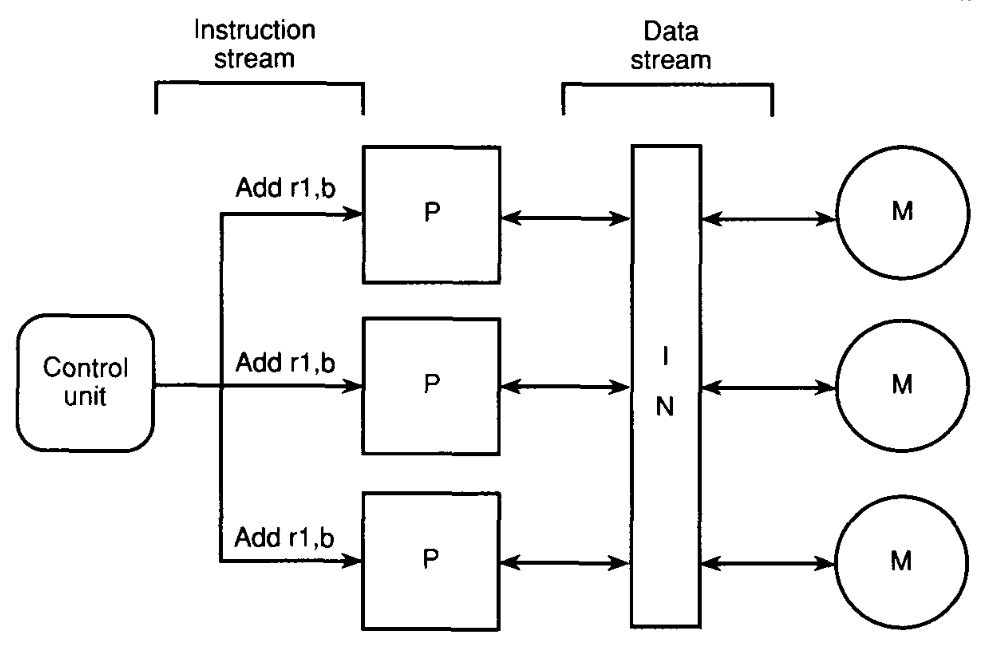 <!-- .element: height="470px" --> Эквивалент SIMD в классификации Флинна. ---- ##### SIMD. Ассоциативный массив <div class="row"><div class="col"> (Content-Addressable <br/> Parallel Processor, CAPP) 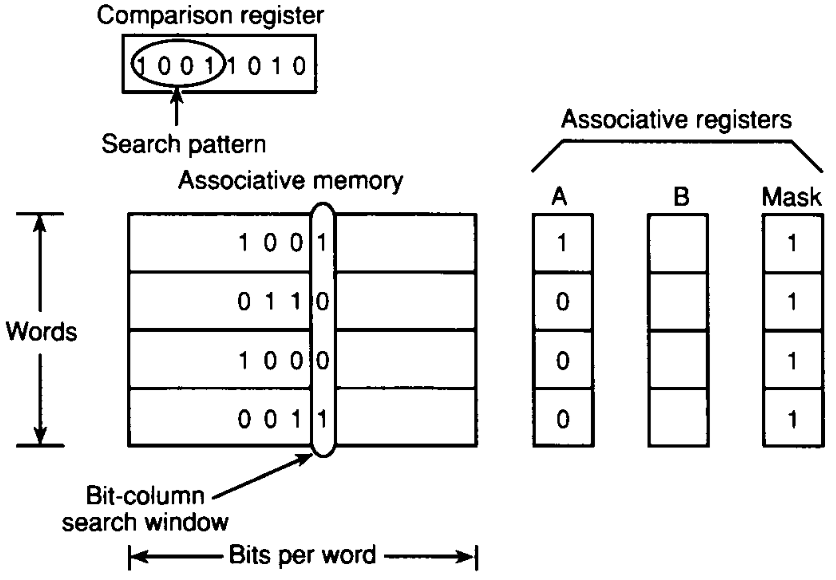 Позволяет быстро искать информацию в массивах данных. Используется в сетевых устройствах. </div><div class="col"> Процессор основанный на ассоциативной памяти (Content-addressable memory, CAM)  </div></div> ---- #### Sync. Систолические архитектуры <div class="row"><div class="col"> Конвейерные мультипроцессоры: 1. данные ритмично поступают из памяти, 1. проходят через сеть процессоров, 1. и возвращаются в память. Синхронизация — через глобальные часы, такт вычислений (не путать с тактовым сигналом). Процессоры объединены локальными связями, и каждый цикл процессоры выполняют короткие неизменные операции. </div><div class="col">  </div></div> ---- ##### Sync. Систолические архитектуры. Пример 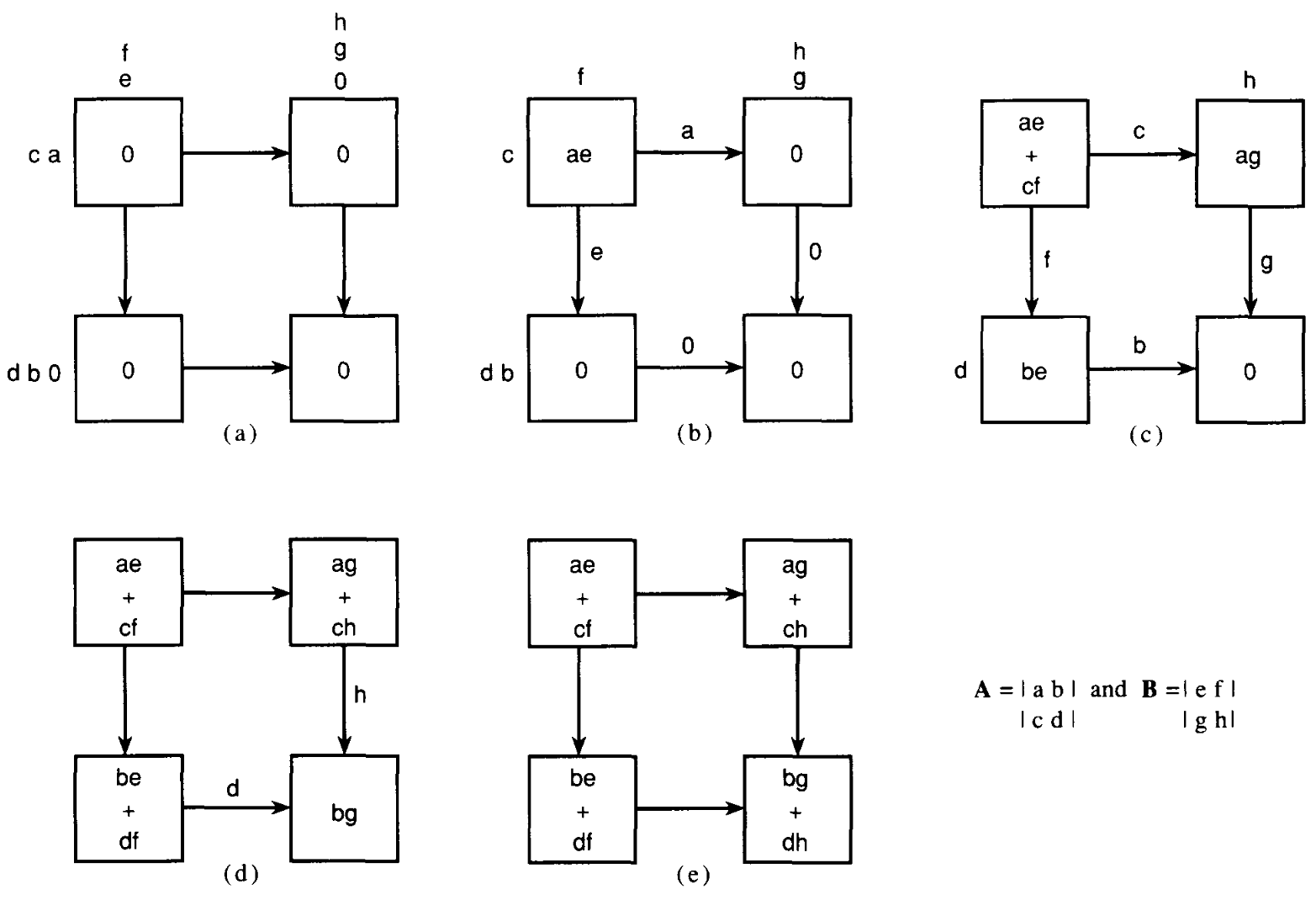 ---- ###### SIMD. Совмещение памяти и Вычислений `*` <div class="row"><div class="col"> Пример: перемножение матриц в нейронных вычислителях. $Out = In \times Parameters$. - параллелизм операций умножения (векторные операции); - минимизация числа передач данных от процессора (вторая матрица загружается 1 раз); - привычный интерфейс (работа с памятью). </div><div class="col"> 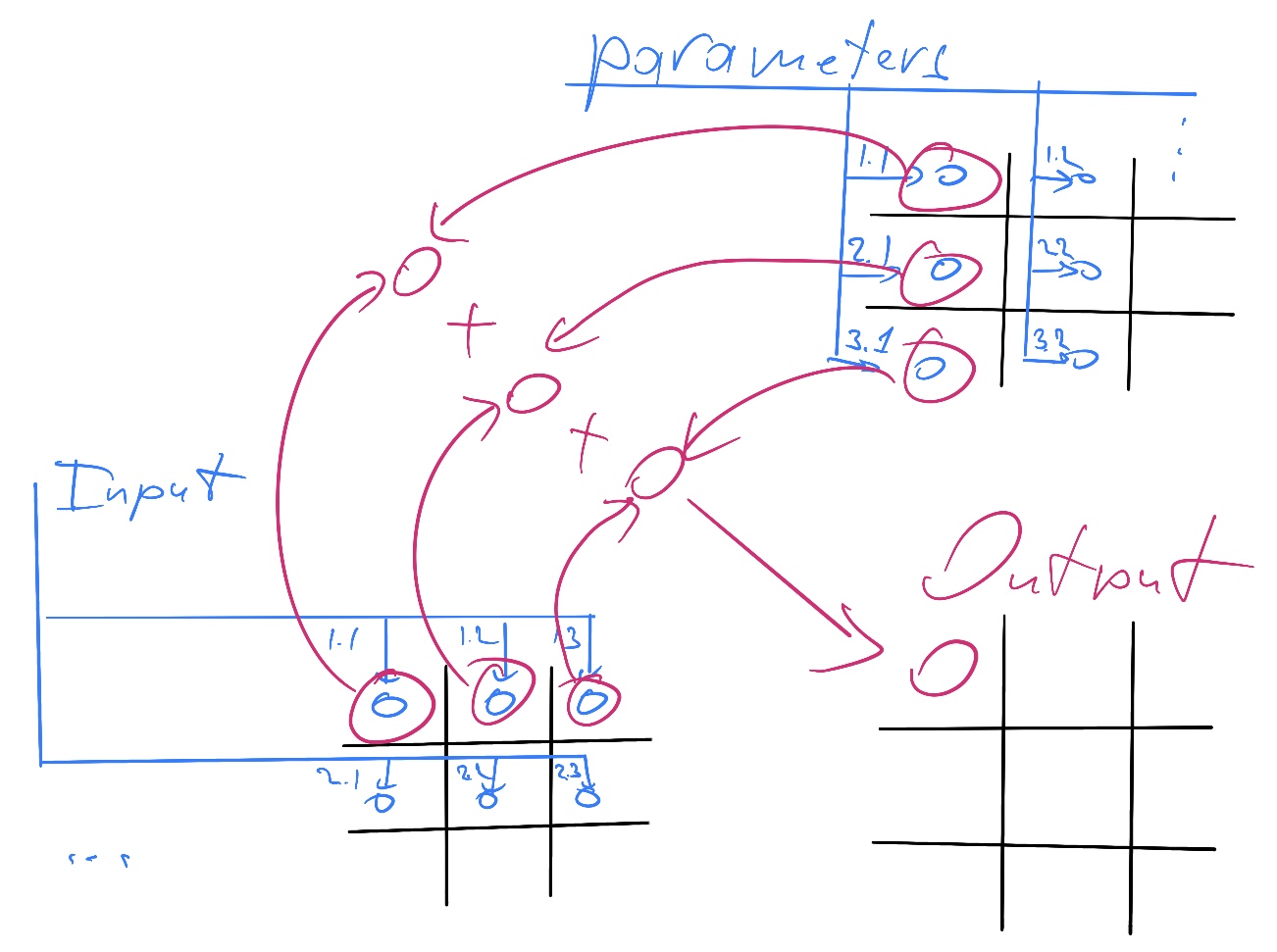 (результат 1.2 на след. слайде) </div></div> ---- 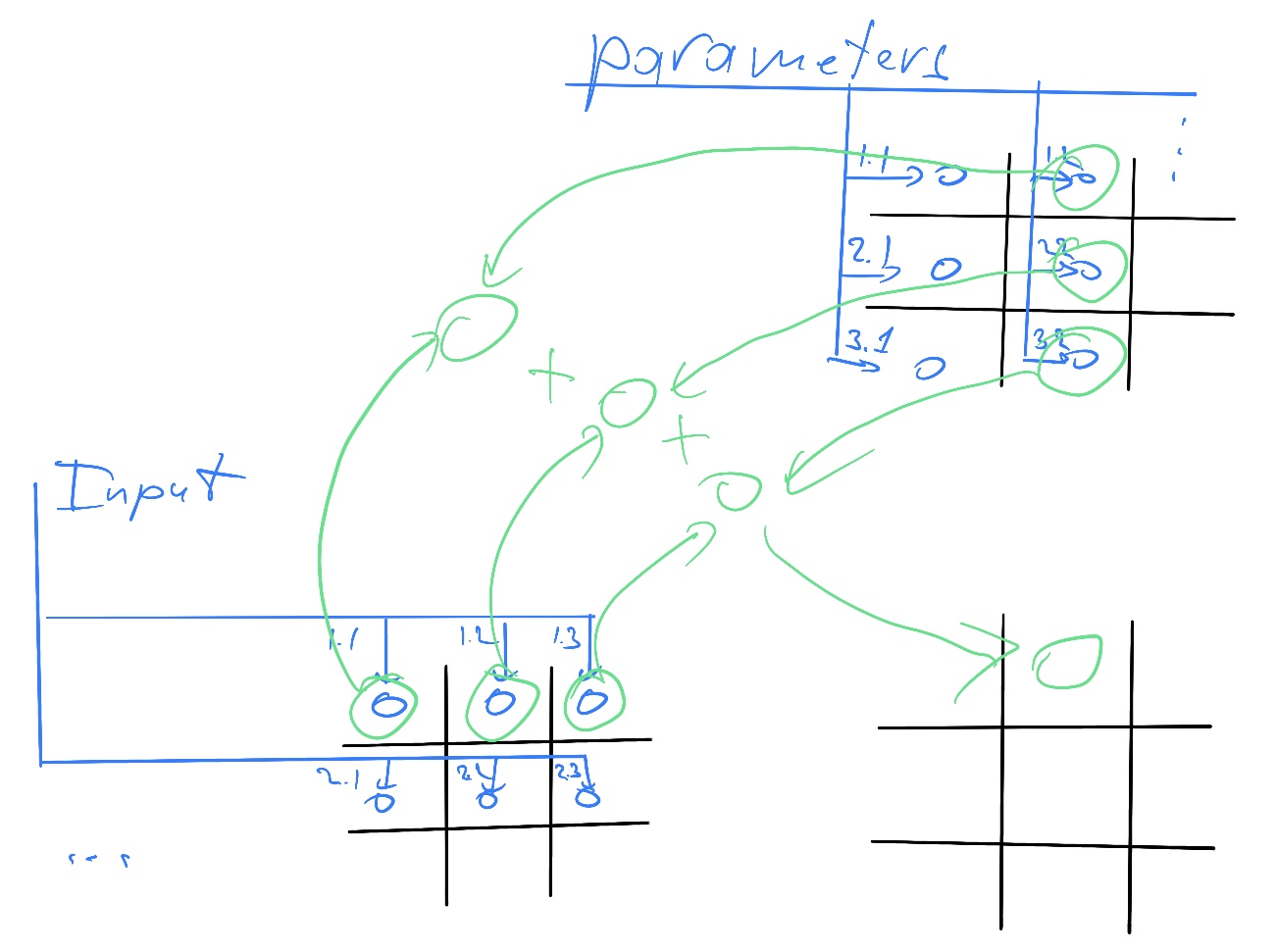 --- ### MIMD архитектура Ключевой вопрос — организация памяти: - разделяемая, - распределённая. Аналогия из современных веб приложений: - синхронизация через единую базу данных; - микросервисная архитектура. ---- #### MIMD. Разделяемая память <div class="row"><div class="col"> 1. Координация совместной работы через общую память. 1. Ключевая проблема: координация доступа, согласование кешей. 1. Примеры подходов: - (a) шинное соединение; - (b) перекрестная шина 2x2; - (c) сеть на кристалле, запрос маршрутизируется от P к M. 1. Широко распространены, так как привычны и прозрачны для программистов. </div><div class="col"> 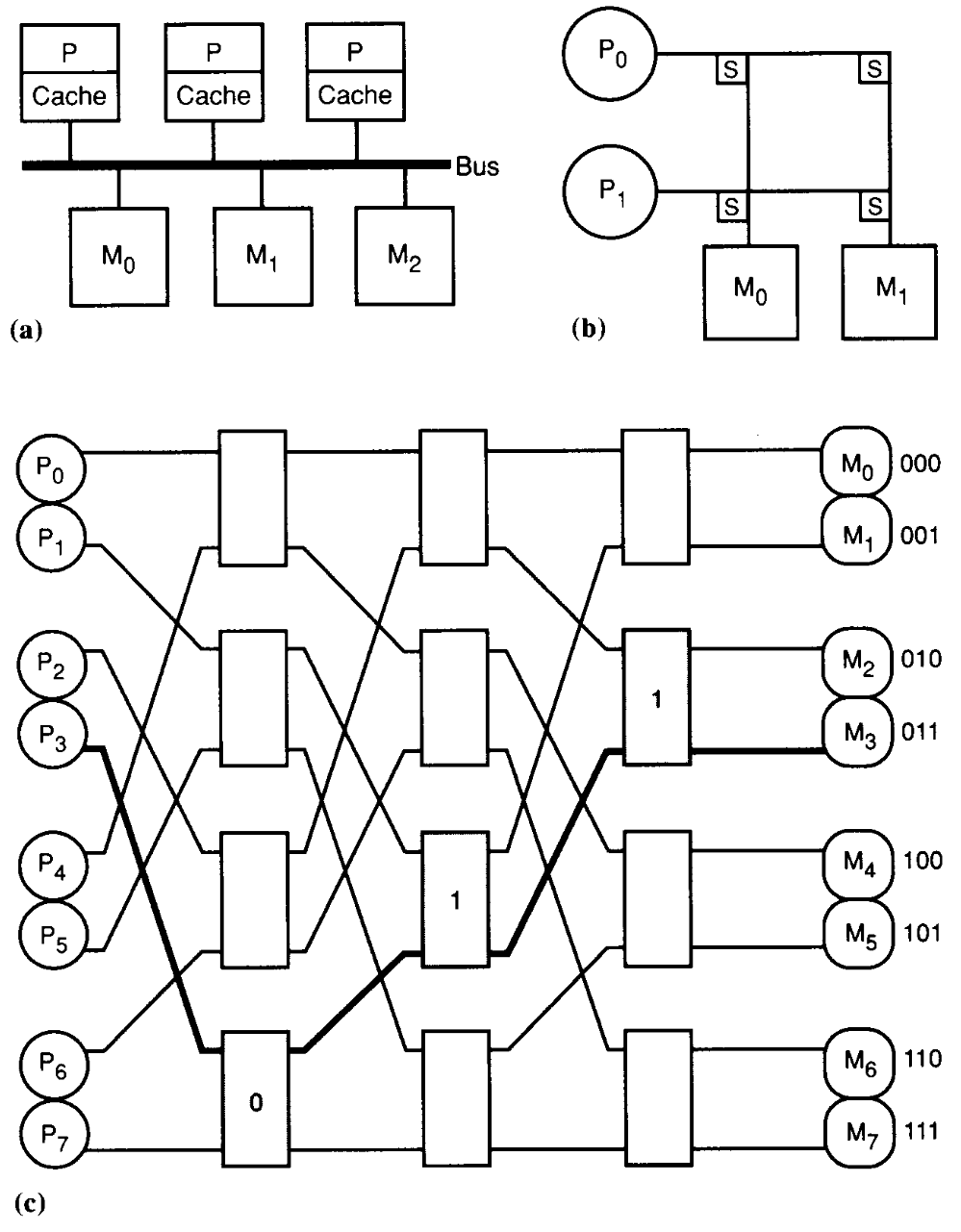 </div></div> ---- #### MIMD. Распределённая память <div class="row"><div class="col"> 1. Координация совместной работы через прямое взаимодействие процессоров. 1. Данные/сигналы явно передаются между процессорами (message passing). 1. Мотивация: обеспечить масштабируемость многопроцессорной архитектуры и доступ к локальным данным процессора. </div><div class="col"> 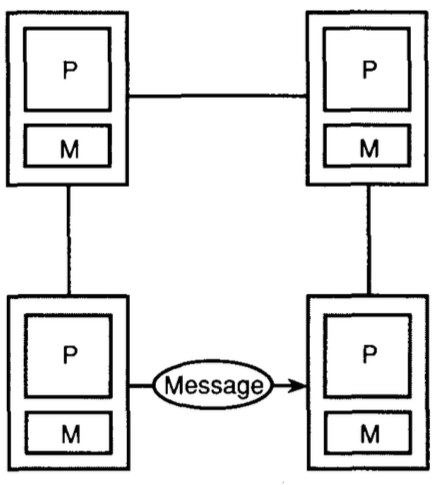 </div></div> ---- ##### MIMD. Распределённая память. Топология Определяется в зависимости от характера потока данных в прикладной задаче. <div class="row"><div class="col"> 1. **Кольцевая** топология + [хорды]. Мало процессоров, передача данных не доминирует. 1. **Ячеистая** / сетка. Соединены соседи + [диагональные] + [кольцевые]. Топологическое соответствие матричным алг. 1. **Дерево**. Алгоритмы поиска и сортировки, обработка изображений, потоковые и редукционные машины. 1. **Гиперкуб**. Коммуникационный диаметр $log_{2}N$. 1. **Реконфигурируемые**. Фиксируем сеть конфигурацией, а не маршрутом. </div><div class="col"> 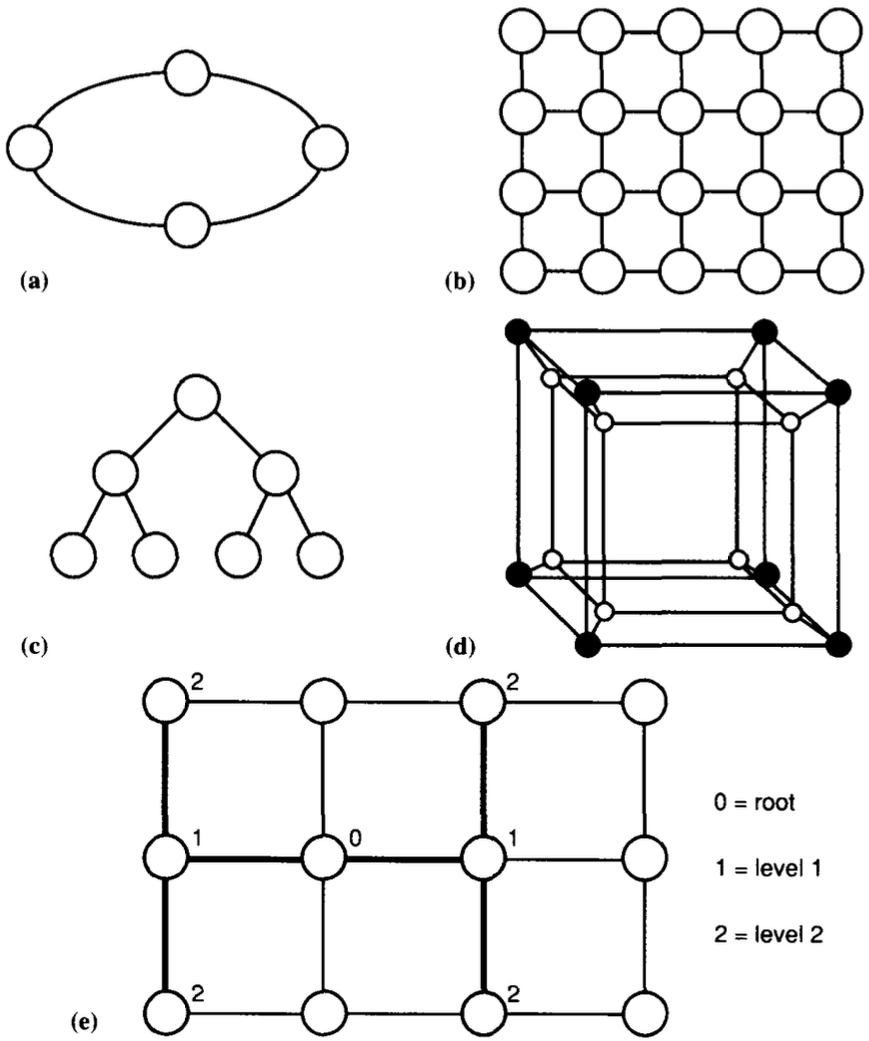 </div></div> --- ### MIMD парадигма (paradigm architectures) Имеется в виду парадигма программирования или точнее — модель вычислений (MoC). - MIMD/SIMD - Потоковая архитектура (Dataflow) - Редукционная архитектура - Wavefront ---- #### MIMD/SIMD <div class="row"><div class="col"> 1. Гибридные архитектуры, где управление MIMD (малые задачи) осуществляется в стиле SIMD (крупные задачи). 1. Отношение ведущий — ведомый (master — slave) может быть представлено деревом: - корень работает как SIMD и распределяет задания; - листья работают как MIMD с локальной памятью. 1. Аналогия: `fork/join`. </div><div class="col"> 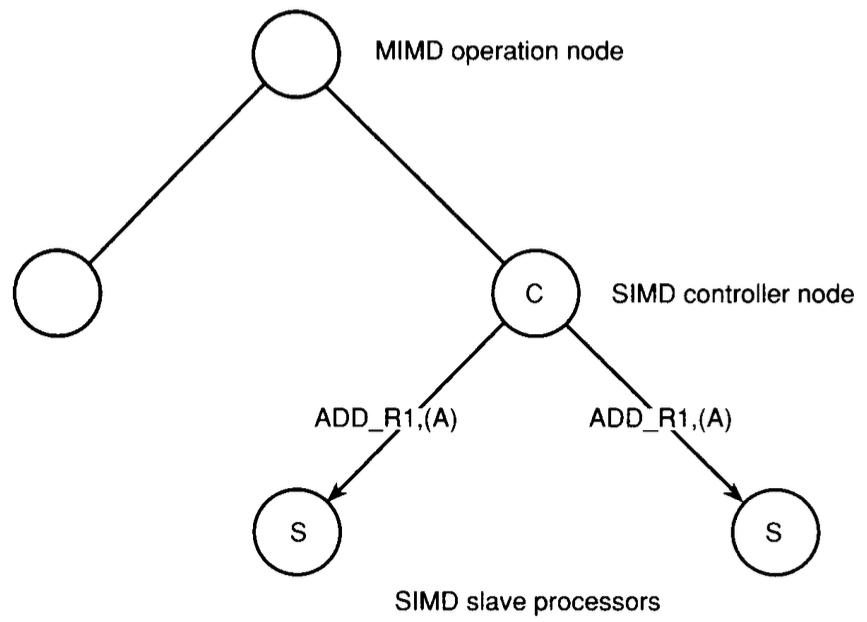 </div></div> ---- ##### MIMD/SIMD. Transport Triggered Architecture (TTA) Processor `*`  <!-- .element height="400px" --> 1. Запуск вычислений инициируется пересылкой данных, управляемой диспетчером. 1. Непосредственное выполнение инструкций — отсутствует. 1. Долгая обработка + быстрая пересылка $\rightarrow$ параллелизм. ---- #### Потоковая архитектура (Dataflow) <div class="row"><div class="col"> <dl> <dt> Потоковые архитектуры </dt> <dd> возможность выполнения и исполнения инструкций определяется исключительно наличием входных аргументов для инструкций. Порядок выполнения инструкций непредсказуем. </dd> </dl> -------------------- 1. Алгоритм представляется в виде графа вычислений. 1. Отсутствует память и канал доступа как "бутылочное горлышко". 1. Проблема — передача данных между узлами. 1. Аналогия: микросервисные архитектуры. </div><div class="col"> 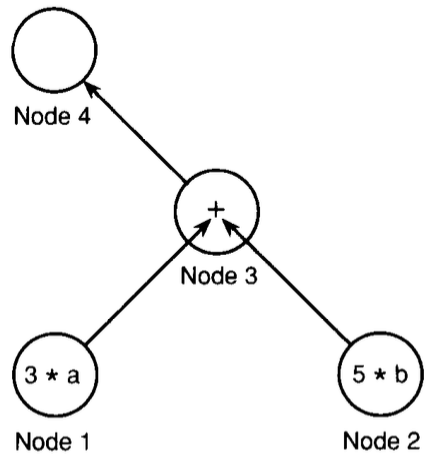<!-- .element height="220px" --> <!-- .element height="270px" --> (реконфигурируемая топология) </div></div> ---- ##### Потоковая архитектура (Dataflow). Устройство <div class="row"><div class="col"> 1. Распределённая память. Топология кольцо. 1. По кольцу посылаются токены (метка + значение). 1. Получатели пересылают токен дальше и сохраняют значение, если являются адресатом. 1. Если задача разблокируется (все необходимые токены получены) — запускается работа. 1. Результат работы отправляется токеном по кольцу. </div><div class="col"> 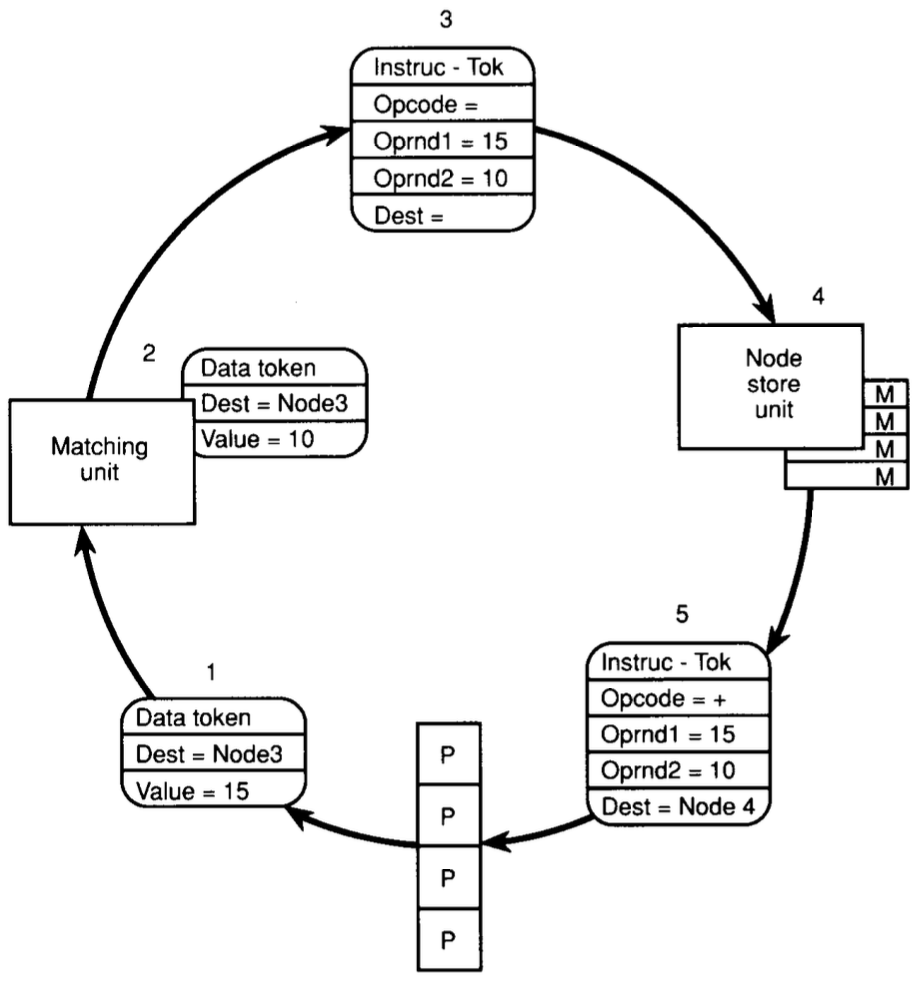 </div></div> ---- #### Редукционная архитектура (Reduction) <div class="row"><div class="col"> <dl> <dt> Редукционные архитектуры (ориентированные на запрос) </dt> <dd> инструкции разрешаются к выполнению, когда их результаты требуются в качестве операндов для уже разрешенных инструкций. </dd> </dl> -------------------- 1. Разрабатывались для параллелизма и функционального программирования. 1. Выполнение: выборка инструкций, замена инструкции на её результат в графе вычислений. 1. Проблемы: ссылочная прозрачность, разворачивание вычислительного графа, нормальные/ленивые вычисления. </div><div class="col">  </div></div> ---- ##### Редукционная архитектура (Reduction). Устройство <div class="row"><div class="col"> 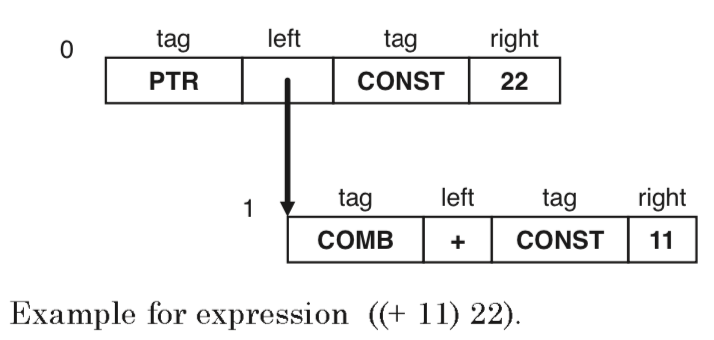 [An Architecture for Combinator Graph Reduction (TIGRE)](https://users.ece.cmu.edu/~koopman/tigre/index.html) </div><div class="col"> 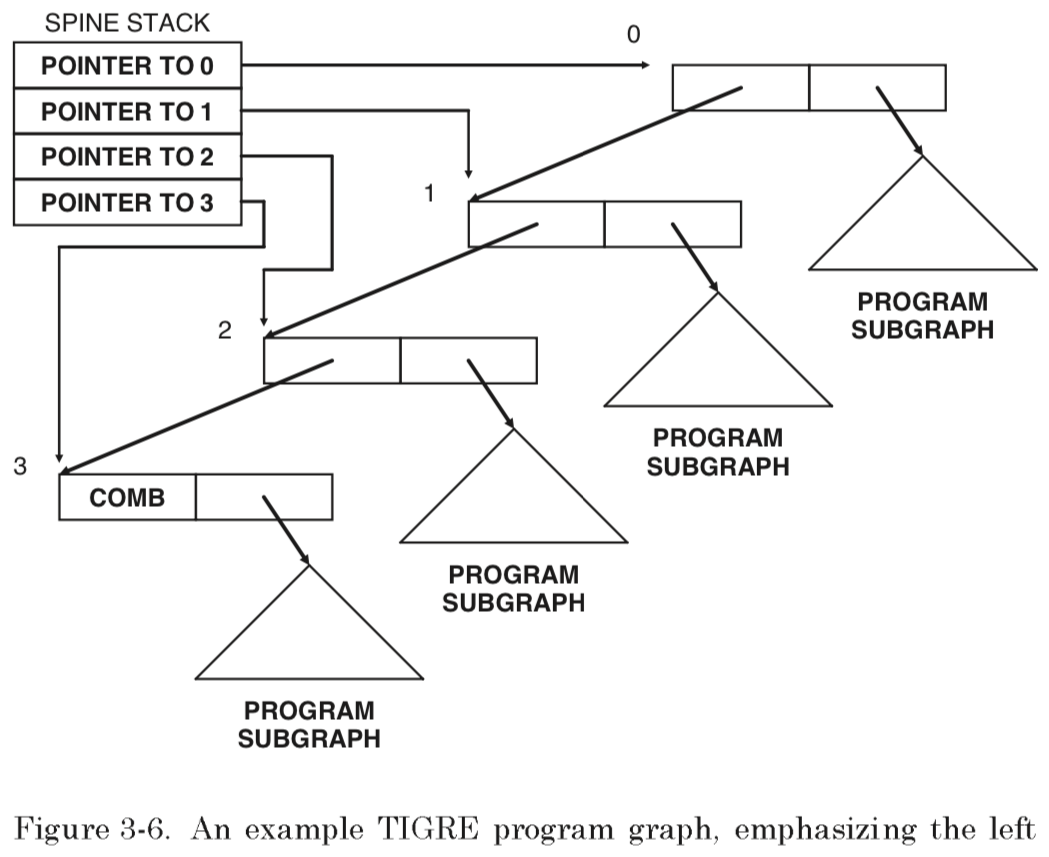 </div></div> Notes: В аппаратуре встречается редко. Часто встречается в мире функционального программирования на уровне Run-Time/Вирт. машины. ---- <div class="row"><div class="col"> #### Wavefront 1. Комбинация систолической архитектуры с асинхронным потоковым исполнением. 1. Управление происходит динамически, за счёт распространения сигнала по сети. 1. Синхронизация и режим работы выстраиваются динамически. 1. Проще в программировании. Лучше масштабируется. 1. Риски переполнения буферов в Run-Time. </div><div class="col">  <!-- .element height="700px" --> </div></div> --- ### Coarse-Grained Reconfigurable Architecture Выводы из классификаций Флинна и Дункана: 1. Огромное разнообразие подходов к построению процессора. 2. Противоречие между пространственными и временными вычислениями (Spatial & Temporal Computation). 3. Противоречие между универсальностью и эффективностью. Выделяется ниша: - Domain-Specific Flexibility ("Предметно-специально гибких"). - Сочетающих пространство и время. - Управляемых конфигурацией и данными (Configuration / Data-driven execution). Заполняется крупно-гранулярно реконфигурируемыми архитектурами — **CGRA**. ---- #### CGRA: Hybrid Spatial & Temporal Computation <div class="row"><div class="col"> CGRA архитектура определяет (снизу-вверх): 1. вычислительные блоки доступны и с какими интерфейсами (данные/управление); 1. коммуникацию между вычислительными блоками; 1. механика управления процессором; 1. механика планирования вычислительного процесса; 1. программы и программирование. </div><div class="col"> 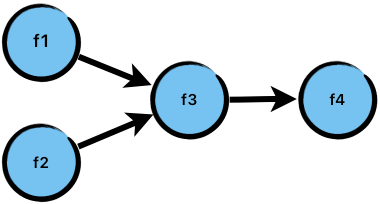 <!-- .element height="150px" --> 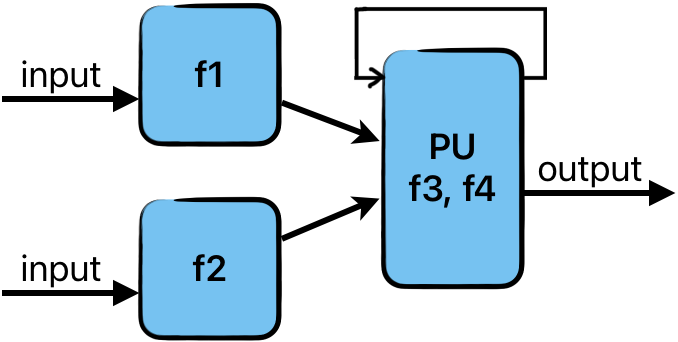 <!-- .element height="150px" --> 1. Крайне разнообразны, не имеют проработанной теории. 1. Являются актуальным направлением в развитии процессоров. </div></div> ---- #### CGRA Classification 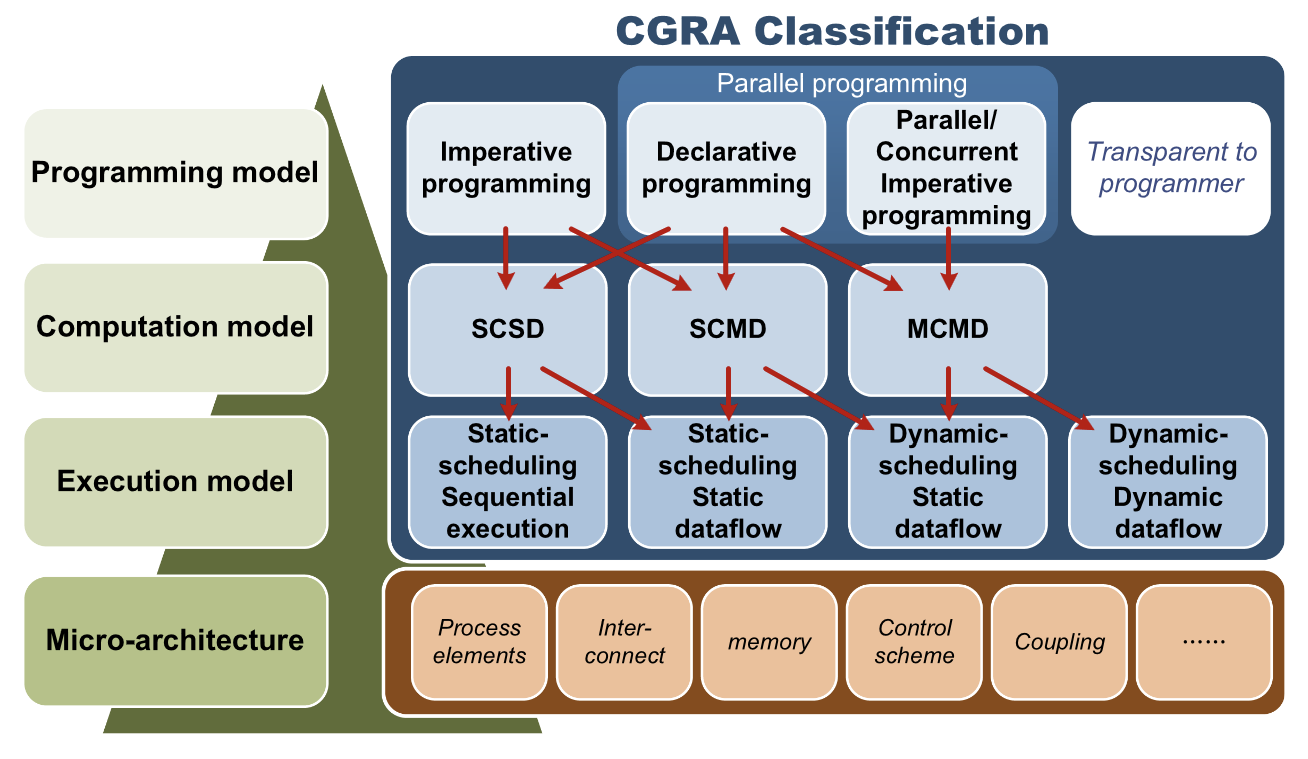 <!-- .element height="450px" --> ---- #### CGRA. Computation model 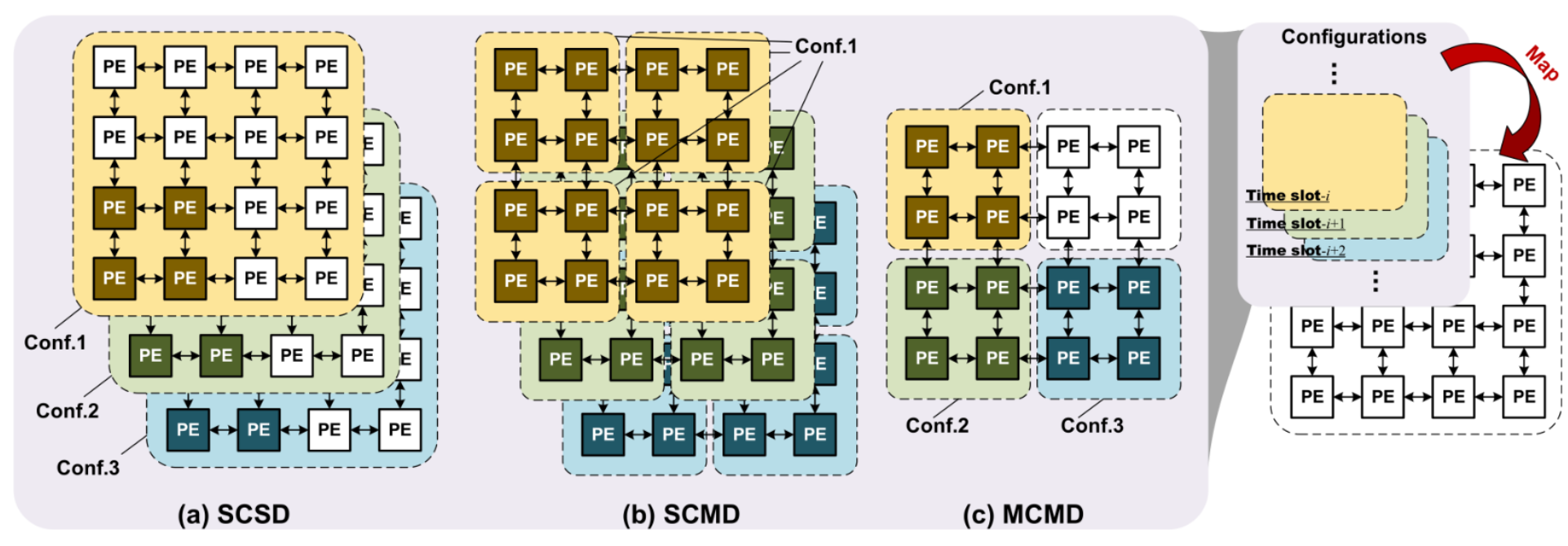 - **SСSD** — single configuration, single data - **SCMD** — single configuration, multiple data - **MCMD** — multiple configuration, multiple data ---- #### CGRA. Execution Model 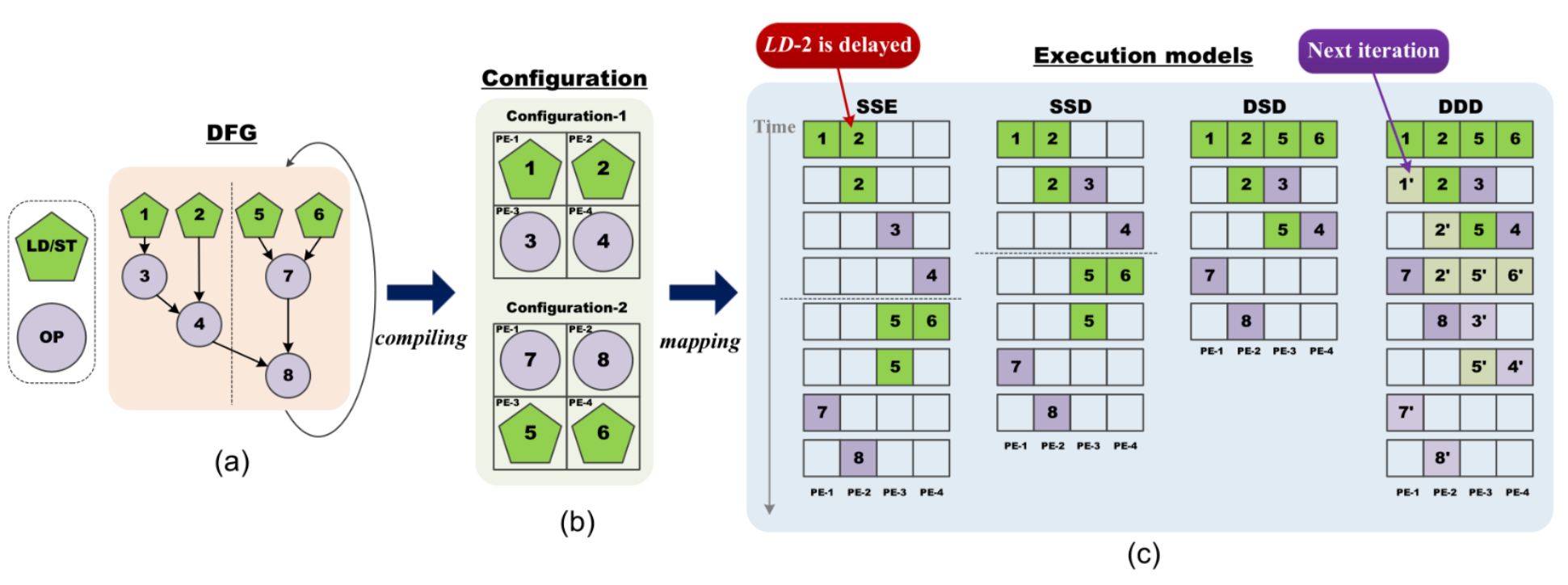 ---- #### CGRA: Challenges & Trends